Spring Cloud Netflix生产实践指南
服务注册生产实践
服务注册的时效性(毫秒级)
服务在启动后,会向eureka server发起注册,应该是在1秒以内的。
会通过SpringCloud额外封装的EurekaAutoServiceRegistration#start()发起注册,这个类的实例被EurekaClientAutoConfiguration定义。
服务发现的时效性(毫秒级和分钟级)
一个服务启动后,发现其他所有的服务需要多长时间?如果其他服务新增了机器,那么又需要多长时间才能发现。
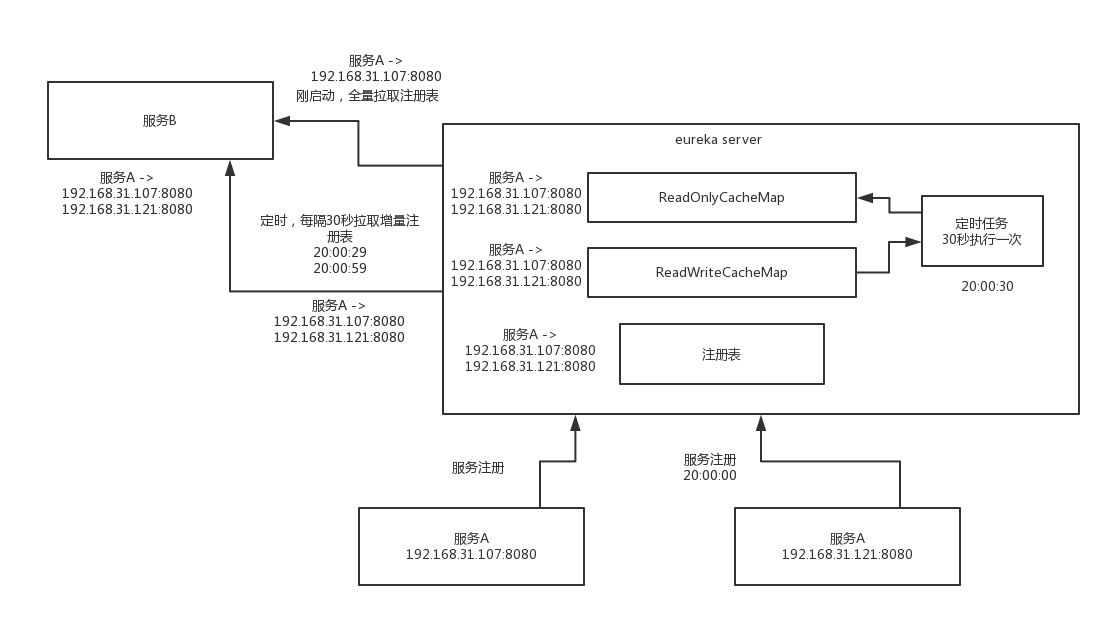
- 服务启动后,会主动拉取全量注册表,可以发现已经注册的服务列表(毫秒级)
- 服务每隔30秒会拉取增量注册表(先走ALL_APPS_DELTA缓存,读不到查queue)
- eureka server 二级缓存,定时任务30秒从readWriterCacheMap同步到readOnlyCacheMap
- 一个服务启动注册后,要30秒才会被其他服务发现(1分钟以内)
eureka的服务发现是分钟级,可通过修改配置减少这个时间:
eureka client端(EurekaClientConfigBean):
1 | eureka.client.registryFetchIntervalSeconds=30 |
eureka server端(EurekaServerConfigBean):
1 | eureka.server.responseCacheUpdateIntervalMs=30 * 1000 |
服务心跳的时效性(30秒)
服务启动以后,会定时发送心跳给eureka server,默认是30秒一次(EurekaInstanceConfigBean)
1 | eureka.instance.leaseRenewalIntervalInSeconds=30 |
服务故障感知的时效性(5分)
在eureka server中,每隔60秒会执行一次evict task(加上JVM gc等原因的补偿时间),判断当前所有的服务实例是否有的实例出现了故障(一直没有发送心跳)。
这个任务的逻辑是,默认90s没有收到过心跳就认为已经过期,但是这里有bug,实际上是90s * 2 = 180s才会认为已经故障了,那么算到这里,eureka server可能要4分钟才能感知到一个服务宕机后认为是下线了。 (而且每次只会摘除最多15%数量的故障实例),
客户端:服务摘除后,会清空readWriteCacheMap的缓存,算eureka server的读写缓存30秒,然后每隔30秒会同步到readOnlyCacheMap里。所以宕机后要被客户端感知到,极端情况下可能要5分钟。
服务下线感知的时效性(1分钟)
在eureka client里,得自己调用一下eurekaClient.shutodwn()方法来进行服务下线。逻辑也是从内存的map里删除,然后放入recentlyChangedQueue队列里,最后让缓存失效。
无论是服务注册、故障、还是下线了,都会将变更记录放进recentlyChangedQueue里,eureka client在30秒的增量更新定时任务里,去合并新的服务列表。readOnlyCacheMap从readWriteCacheMap同步的时间也是30秒。所以服务最长可能60秒才能感知到服务的下线。
eureka server自我保护机制(不要用)
eureka的自我保护机制,充斥着大量的hash code硬编码,写死你的心跳间隔时间是30秒,1分钟2次,通过统计服务的心跳次数来判断自己是不是网络故障了。这个根本就是很严重的bug,无法在生产环境使用。
直接在配置中关闭
1 | eureka.server.enableSelfPreservation=false |
eureka server集群的负载均衡(按配置顺序)
服务在注册的时候,如果在yml里配置了多个eureka server,会按顺序用第一个eureka server的机器发起注册,只有在第一个机器挂掉的情况下,在重试一定次数失败以后,才会尝试用第二台机器。
那如果第一台又恢复了呢,其实还是会一直用第二台,除非第二台死掉了,才会重试别的机器。
这些重试的逻辑的源码,都在RetryableEurekaHttpClient类里
1 |
|
eureka server集群同步的时效性(1秒内)
在eureka server收到注册请求的时候,就会将注册数据同步到其他节点,它会循环所有配置的集群节点信息,并排除自己。然后带上服务实例的注册信息,分别调用其他节点的注册接口,并且这里包含了一个注册逻辑的批处理。
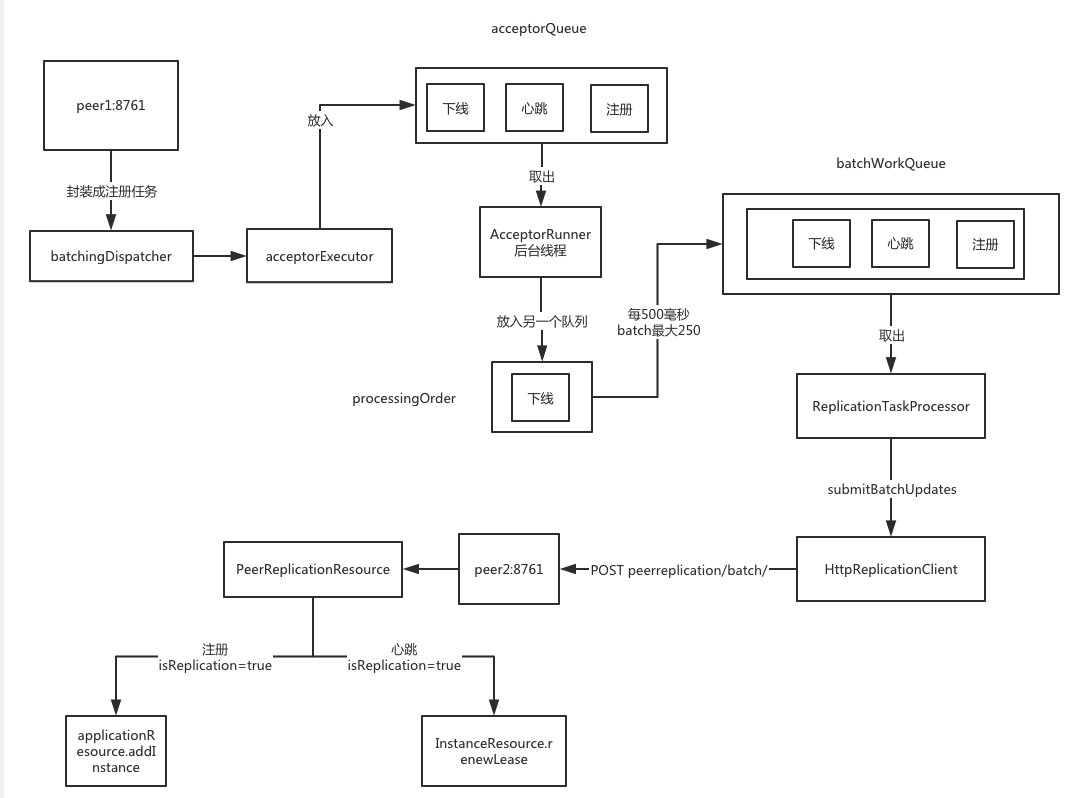
可以看到,因为有一个批处理的机制,每500毫秒以内的请求会统一打包处理,所以集群间的数据同步,是一秒以内完成同步。
服务调用生产实践
Ribbon+Eureka服务发现与故障的时效性
服务正常上线/修改,最大可能会有60s滞后
1 | 30(readWriterCacheMap)+30(client fetch interval)+30(ribbon)=90 |
前面已经分析了Eureka本身的时效性,刚启动发现其他服务是毫秒级,发现新注册的服务是分钟级。那么在结合Ribbon使用后,他有一个PollingServerListUpdater,这个是每30秒从eureka client同步一次到Ribbon的缓存中,所以一个新注册的服务要被Ribbon感知到,极端情况下需要90秒。
服务异常下线:最大可能会有300s滞后
1 | - 定时清理任务每eureka.server.evictionIntervalTimerInMs(默认60)执行一次清理任务 |
那如果某一个服务宕机了,Eureka Client感知到的时间是5分钟,再加上Ribbon的PollingServerListUpdater的30秒,Ribbon在极端情况下是需要5.5分钟才能感知到。
Ribbon负载均衡算法
Ribbon默认是用ZoneAwareLoadBalancer,默认算法就是轮询
超时和重试
在早期的Feign也有重试的模块,但是后来发现和Ribbon冲突了,于是SpringCloud团队在后面的版本将Feign的重试设置为NERVER_RETRY了。具体的缘由,可以看下这篇文章:http://www.itmuch.com/spring-cloud-sum/spring-cloud-retry/
1 | ribbon: |
feign的超时时间优先级更高
1 | feign: |
Ribbon预加载
网关的项目第一次访问的时候总是会超时,是因为在第一次访问的时候,Ribbon会去调用eureka-client里的服务列表,所以这里会消耗一些时间,而zuul默认超时时间又是1秒,所以加上下面的参数,让Ribbon提前加载好。
1 | ribbon: |
Zuul+Ribbon+eureka感知服务上线和故障的时效性
这块儿和Ribbon+Eureka服务发现与故障的时效性是一样的
Zuul降级和异常
Error Filter错误处理和降级
Zuul超时
1 | ribbon: |
Hystrix的超时时间应该大于Ribbon的超时时间,加上Ribbon的重试机制,基于上面的参数计算,(ribbon.ConnectTimeout + ribbon.ReadTimeout) * (ribbon.MaxAutoRetries + 1) * (ribbon.MaxAutoRetriesNextServer + 1)。
Hystrix的超时时间应该是设置为8秒。
总结
本文系统讲解了技术要点,通过学习掌握核心知识和实践方法。