Eureka源码解析 05:集群初始化与同步
eureka server集群相关源码分析
前面的文章分别介绍了服务启动、注册、下线、故障和自我保护机制等原理,这里就开始介绍集群相关的东西。
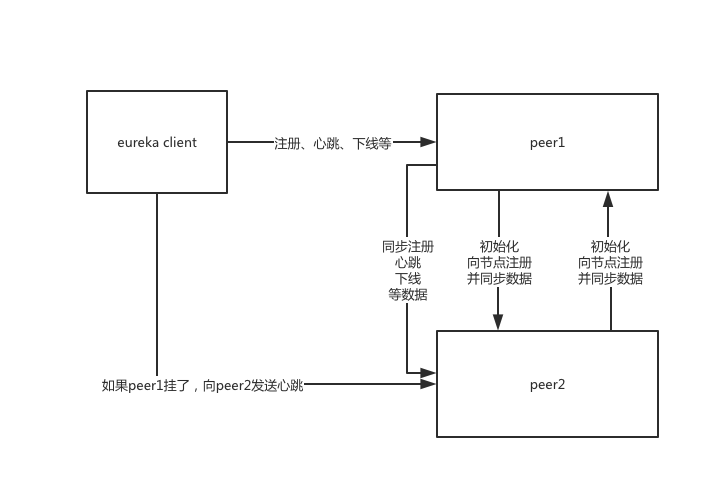
集群信息初始化
eureka server集群高可用,是需要相互注册的,然后会相互同步服务实例列表。前面分析eureka server启动流程的时候,在EurekaBootstrap的初始化代码里有一段和集群相关的代码。
1 | // 第五步,处理peer节点相关的事情 |
这个PeerEurekaNodes的start方法,在DefaultEurekaServerContext的初始化代码中被调用。它会解析配置文件中配置的其他eureka server的地址,基于URL地址构造一个一个的PeerEurekaNode,然后将其他节点的信息保存到本地。默认是每隔10分钟,会定时基于这个配置刷新集群配置信息。
集群数据同步
在初始化集群的节点信息后,还需要同步其他节点的注册表到本地。也就是EurekaBootstrap初始化代码里的registry.syncUp();,因为自己本来也是一个eureka client,所以在启动初始化的时候,就已经从任意一个其他的eureka server节点拉取到注册表在本地,在这里只需要将缓存的实例信息取出来,然后在挨个本地注册一次。
1 | for (int i = 0; ((i < serverConfig.getRegistrySyncRetries()) && (count == 0)); i++) { |
那么在源码里我们可以看到,这里有一个重试的机制,里面还包含了sleep的代码,其实就是因为eureka client在本地的缓存可能还没有生成成功,就先执行了这里的代码,所以会等到30秒后再重试,看是否缓存已经有了数据。
这里也包含了上一节中提到的统计服务实例数量,后续会用来计算预期收到的心跳次数。
注册、下线、故障集群间同步
注册
还记得eureka server处理注册请求的代码,在ApplicationResource.addInstance方法中,调用PeerAwareInstanceRegistryImpl.register方法进行注册,那么replicateToPeers方法,就会将注册数据同步到其他节点,此时这里的isReplication参数是false。
1 | public void register(final InstanceInfo info, final boolean isReplication) { |
跟到这个方法里面看一下,它会循环所有配置的集群节点信息,并排除自己。然后带上服务实例的注册信息,分别调用其他节点的注册接口,但是这里和client调用是有区别的,他底层的调用发起类是JerseyReplicationClient,在发起http请求的时候,一定会带上请求头:webResource.header(PeerEurekaNode.HEADER_REPLICATION, "true");,那么其他节点在收到请求的时候,上面的isReplication就是肯定是true了。当isReplication是true的时候,不会像其他节点进行注册。
1 | switch (action) { |
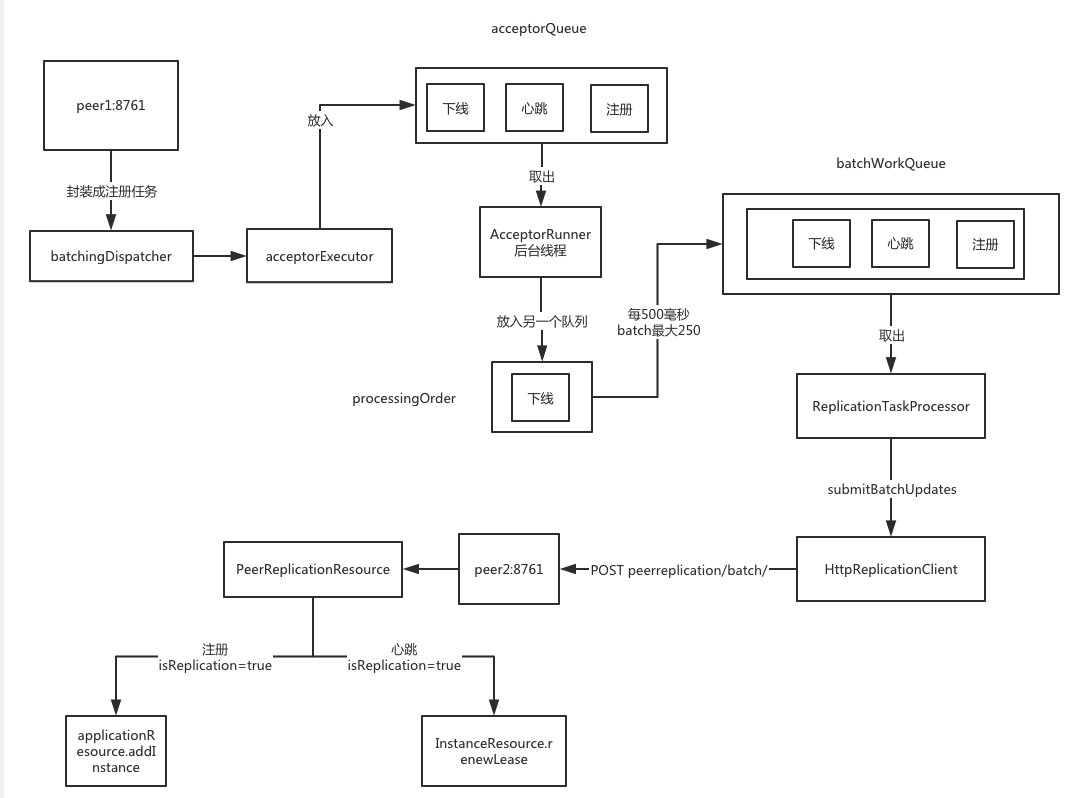
注册逻辑的批处理
跟到node.register(info);里去看,这块代码有点复杂,他用了一个三层队列做了一个批处理请求。
- 集群同步的机制:client可以找任意一个几点发送请求,然后这个server会将请求同步到其他所有的节点上去,但是其他的server仅仅只会在本地执行,不会再往其他节点同步。
- 数据同步的异步批处理机制:有三个队列,第一个队列纯写入(acceptorQueue),第二个队列用来根据时间和大小来拆分队列(processingOrder),第三个队列用来放批处理任务(batchWorkQueue)—>任务批处理机制。
流程如下图所示。
总结
在看完Eureka集群的源码以后,关于Eureka的核心概念涉及到的源码已经分析完成。在SpringCloud中,其实只是做了一层简单的封装,比如把配置文件从读取properties文件改成了从application.yml里,然后利用SpringBoot的自动装配去做了一些自动配置,并没有什么新鲜的东西。下面一张图总结下eureka 核心流程和原理
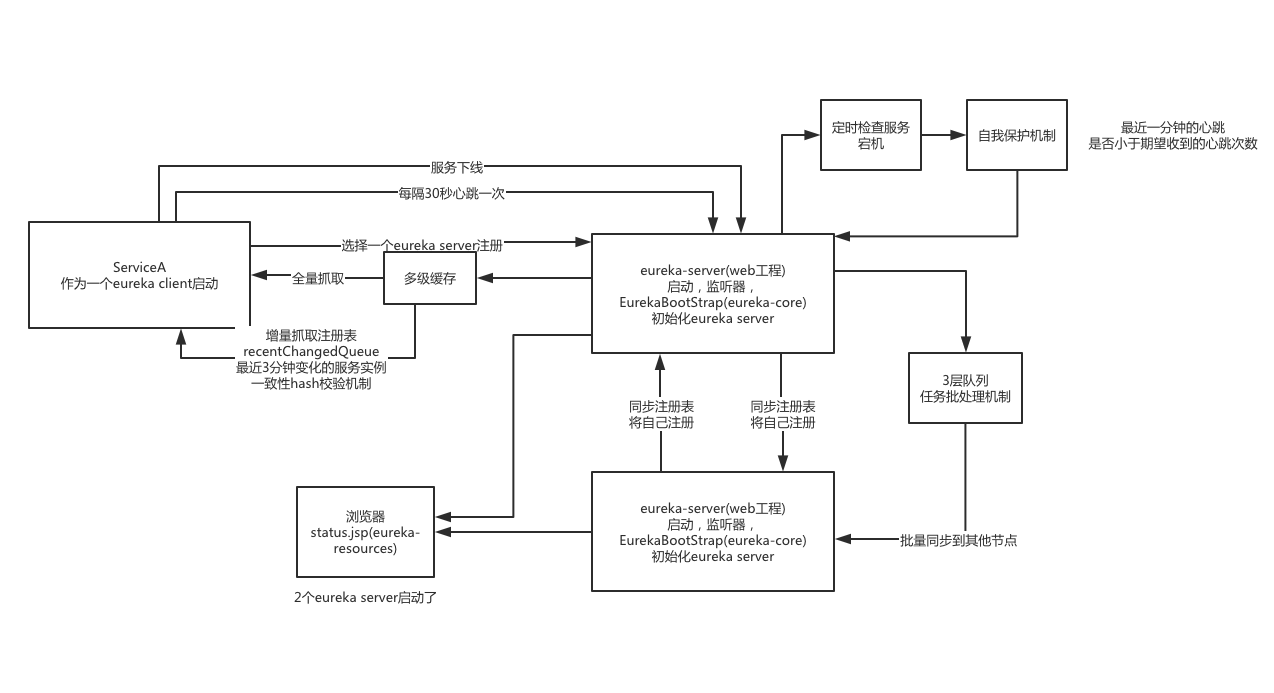
- eureka server启动:注册中心
- eureka client启动:服务实例
- 服务注册:map数据结构
- eureka server集群:注册表的同步,三层队列任务批处理机制
- 全量拉取注册表:多级缓存机制,
- 增量拉取注册表:一致性hash比对机制,recentChangedQueue
- 心跳机制:服务续约,renew,刷新时间
- 服务下线:cancel
- 服务故障:expiration,eviction
- 自我保护机制:自动识别eureka server出现网络故障了,上一分钟心跳次数少于期望的心跳次数。
- 控制台:jsp页面。
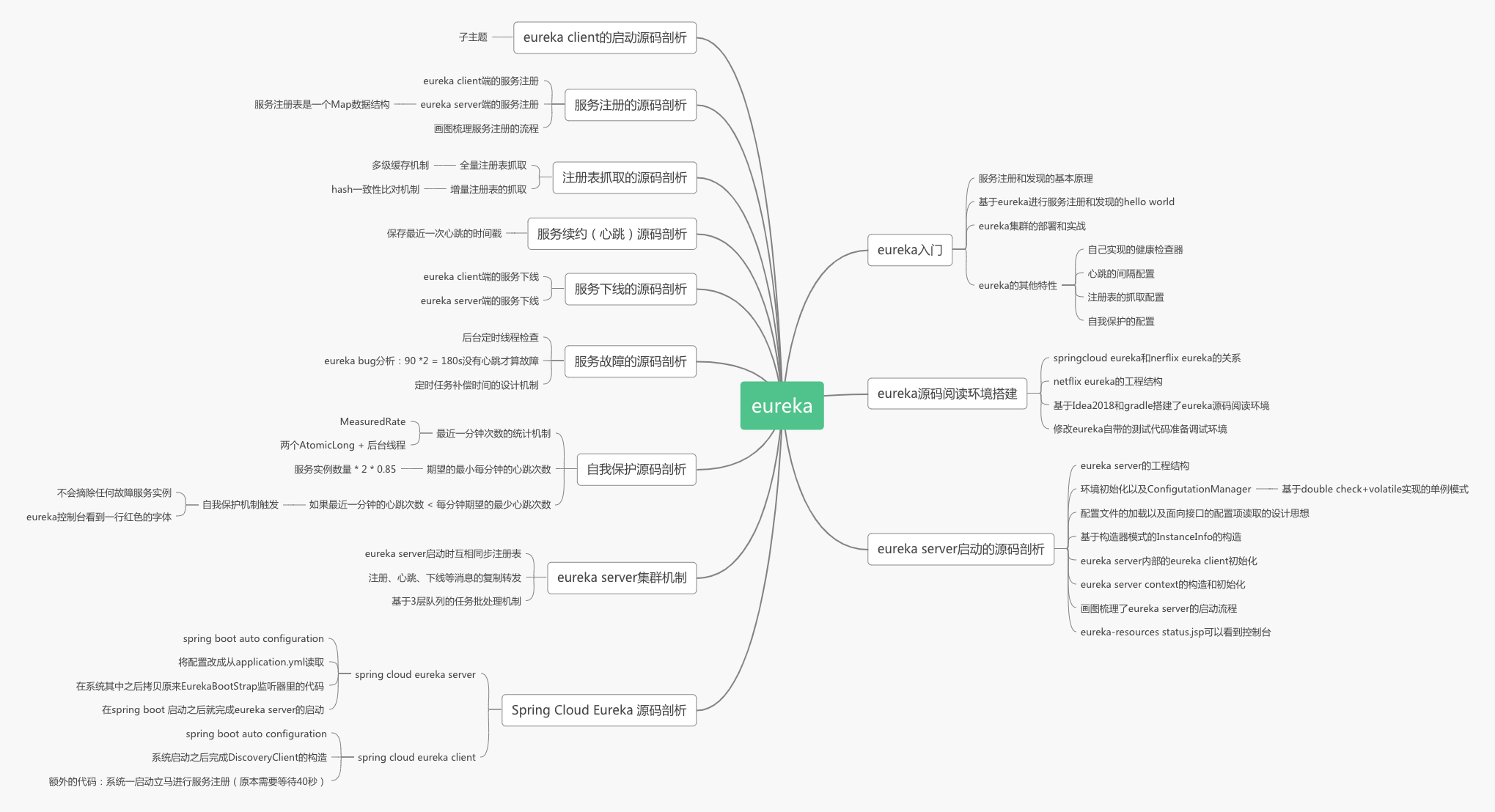
总结
本文系统讲解了技术要点,通过学习掌握核心知识和实践方法。