Spring Cloud健康检查陷阱:线上故障排查实录
记一次线上故障排查并解决(Spring Cloud健康检查的坑)
今天下班在回家路上的时候,同事反馈他们的生产环境项目不停的在输出错误日志,一时半会没有找到原因,让我帮忙看看。我到家后登录VPN,打开了kibana查看日志,确实一直在报错,错误日志如下:
1 | Caused by: java.io.IOException: 断开的管道 |
搜索ERROR级别日志,看到的全是这个日志,而且有两个项目都在输出这个错误日志,询问同事后确定了几个问题:
- 项目近期没有升级
- 这两个项目当前都没有人访问,也就是没有接口流量
- 这个日志似乎是有周期性的输出,1分钟~3分钟不等
记录一下我自己的排查思路,首先项目没有流量,也没有人访问,但是这个错明显是有接口请求,并且是因为客户端主动断开链接导致的,这一点可以确定。那么再结合周期性的错误日志输出,我首先想到的是不是采集监控的端点,或者是健康检查的端点出问题了,于是我登录堡垒机,测试了一下问题项目的采集监控数据的接口,没有问题,健康检查端点也没有问题,都是可以访问的。
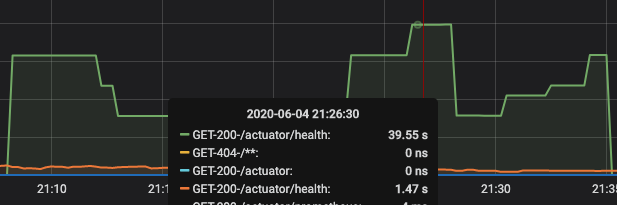
我们的项目是SpringCloud的,所以健康检查端点是:/actuator/health,但是我多刷新了几次,发现有的时候很慢,有的时候很快,慢的时候能达到十几二十秒,健康检查的结果才出来。因为我们的项目是接入了prometheus的,紧接着我又去看了下监控,没有发现问题(监控排除了健康检查端点的访问情况,因为如果是SLB的话每秒会检查10+次),于是我将Grafana中的条件做了调整,得到了健康检查端点的耗时情况。
问题原因
可以看得出来,健康检查端点的耗时确实很长,基本可以确定,上面异常产生的原因是因为consul在对服务进行心跳检查的时候,超时了。所以consul的agent主动断开了/actuator/health的请求,所以得到了 java.io.IOException: Broken pipe的错误。

这一点从监控数据原文里也得到了确认,是健康检查的端点在输出异常日志。
为什么健康检查端点会超时
现在知道了原因,但是这只是表面现象,为什么健康检查会超时?这不太正常,之前都是好好的,为什么突然开始就一直超时了,于是我开始观察健康检查里都有些什么内容,发现有一个可能会比较耗时的东西。
1 | { |
然后我对比了这两个出问题的项目,他们都有邮件的健康检查,我问了下同事,是不是只有这两个项目会用到发邮件的功能,而其他项目没有,同事确认说是的。
基本可以确认,就是因为邮件的健康检查导致的,可能因为网络或是什么原因,导致邮件服务器的健康检查比较慢,从而导致健康检查的端点也非常耗时。
所以联系了运维的同事,加上了以下配置,关闭了邮件的健康检查。因为邮件并不是核心的功能,所以先关闭掉,验证一下是否能解决问题。
1 | management.health.mail.enabled=false |
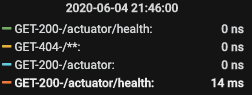
在加入配置关闭邮件服务器的健康检查以后,重启服务,观察了5分钟日志,发现一切恢复如初,没有产生新的异常日志,健康检查的端点,也变得非常快了。
结论
本次故障是因为邮件服务器的健康检查很慢,导致consul对服务进行心跳检查的时候超时,主动断开连接,然后定期的输出了 java.io.IOException: Broken pipe的异常日志。
关于SpringCloud提供的健康检查机制,其实大多数情况下,好多功能的检查都可以关闭,按需打开,举个例子,如果Redis挂掉了,这里整个服务的健康检查就会是DOWN了,会直接导致其他服务无法调用,但是实际上在业务中如果Redis挂掉的话,我们是会去做降级从数据库查询的,仍然可以为其他服务提供调用。
所以我们在项目里,完全可以把这些第三方中间件的健康检查默认给关闭掉。按需打开必要的健康检查选项。
1 | management: |
总结
本文系统讲解了技术要点,通过学习掌握核心知识和实践方法。