Eureka源码解析 04:心跳与自我保护机制
服务心跳流程分析
eureka client每隔一定的时间,会给eureka server发送心跳,保持心跳,让eureka server认为自己还活着。
心跳在代码里,叫做续约。
还是在DiscoveryClient初始化的时候,有一个心跳的定时任务,由
HeartbeatThread执行。默认值是每隔30秒去发送一个心跳。DEFAULT_LEASE_RENEWAL_INTERVAL
接下来是用jersy去给eureka server发送心跳的http请求。
1
httpResponse = eurekaTransport.registrationClient.sendHeartBeat(instanceInfo.getAppName(), instanceInfo.getId(), instanceInfo, null);
请求的地址是:
PUT apps/{appName}/{id}我们根据这个接口去找下是什么类处理的请求,这个又是让我好一顿找:在ApplicationsResource里有个
@Path("{appId}"),这里已经组成了路径apps/{appId},然后在ApplicationsResource里边又有一个``@Path(“{id}”)方法,到这里就是apps/{appId}/{id}`,是不是刚好符合客户端的请求路径,但是还是没有定位到PUT方法在哪里,继续看InstanceResource里的renewLease方法,配合参数看下,终于才找到了server端处理心跳逻辑的代码。不得不说这个隐藏的真是比较深,你看那个getInstanceInfo方法,你很难想到这个get方法只是一个路径的节点,具体的处理还得继续往里跟。应该是也因为我不熟悉jersy这个框架,不知道怎么快速定位一个mvc路径的执行代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// ApplicationsResource
public ApplicationResource getApplicationResource(
String version,
String appId) {
CurrentRequestVersion.set(Version.toEnum(version));
return new ApplicationResource(appId, serverConfig, registry);
}
// ApplicationResource
public InstanceResource getInstanceInfo( String id) {
return new InstanceResource(this, id, serverConfig, registry);
}
// InstanceResource
public Response renewLease(
String isReplication,
String overriddenStatus,
String status,
String lastDirtyTimestamp) {通过注册表的renew方法,完成服务续约的逻辑。registry.renew,实际还是进入AbstractInstanceRegistry.renew这个方法里。
用appName获取服务注册表那个map,做了一些检查。最后执行续约的逻辑(leaseToRenew.renew();)其实就是更新了一下lastUpdateTimestamp的时间,加上了duration。
1
2
3Map<String, Lease<InstanceInfo>> gMap = registry.get(appName);
// 一些代码
leaseToRenew.renew();
服务下线流程分析
下面看一下DiscoveryClient的shutdown方法的逻辑。
在eureka client里,得自己调用一下eurekaClient.shutodwn()方法来进行服务下线。关注里边的unregister();方法。
1
EurekaHttpResponse<Void> httpResponse = eurekaTransport.registrationClient.cancel(instanceInfo.getAppName(), instanceInfo.getId());
对应的路径是,
DELETE apps/{appName}/{id},和上面一样,是在InstanceResource类里的cancelLease方法。最后跟着源码里走,执行的的逻辑是AbstractInstanceRegistry.internalCancel方法。
取到注册表的map,直接调用remove从map里给移除了。
1
2
3Map<String, Lease<InstanceInfo>> gMap = registry.get(appName);
....
gMap.remove(id);然后调用了leaseToCancel.cancel();,设置了evictionTimestamp时间。
在recentlyChangedQueue里新增了一条服务实例变更记录,保留3分钟。(用于在客户端进行增量更新的时候进行合并)
调用invalidateCache,让缓存失效,从readWriteCacheMap里全部清理掉。会有定时任务每隔30秒让readOnlyCacheMap和readWriteCacheMap进行同步。这部分逻辑在上一篇文章有分析到。
下次所有的eureka client来拉取增量注册表的时候,就会返回recentlyChangedQueue里的数据,然后在本地进行合并,比对hash值,再决定是否重新拉取全量注册表的逻辑。
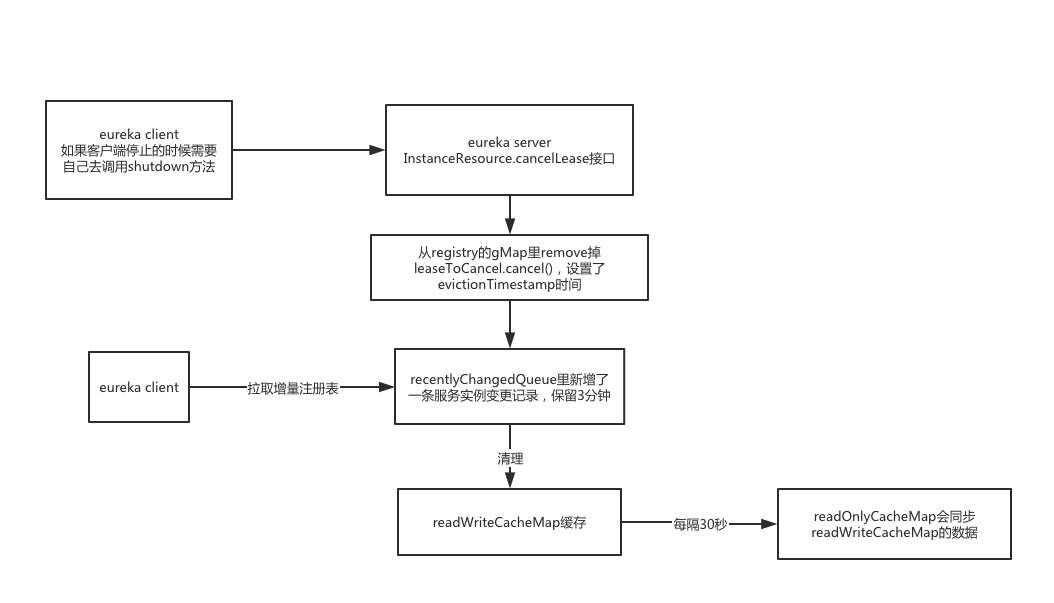
这里再一次体现了,无论是服务注册、故障、还是下线了,都会将变更记录放进recentlyChangedQueue里,eureka client在30秒的增量更新定时任务里,去合并新的服务列表。readOnlyCacheMap从readWriteCacheMap同步的时间也是30秒。所以服务最长可能60秒才能感知到服务的下线。
服务故障流程分析
如果客户端在故障后,没有通知eureka server服务下线。那么就需要用到eureka server自己的故障感应机制,以及服务实例摘除的机制。
eureka server是靠心跳来感知服务是否存活,如果在一定时间内没有收到心跳,那么就认为服务已经宕机了,此时会修改服务状态,并进行摘除。
可以判定,肯定是有一个定时任务,在定时的判断。就是EurekaBootStrap初始化方法里的这行代码:
1 | registry.openForTraffic(applicationInfoManager, registryCount); |
1 | protected void postInit() { |
每隔60秒,会执行一次任务,判断服务实例的租约是否已经过期了,虽然定时任务是60秒一次,这里有个getCompensationTimeMs();方法,计算上次心跳,到这次任务执行的时间差到底是多少,从而保证准确的计算过期时间,因为可能jvm gc原因或者时钟原因,并没有刚好60秒执行这次的任务。
1 | long getCompensationTimeMs() { |
实际上,要3分钟没有收到心跳,才会剔除一个服务的实例。
接着后面就是拆除服务实例的代码
1 | // 一次性不能摘除太多的实例,因为有可能是eureka server节点自己的网络故障原因,导致没有心跳 |
最后调用internalCancel(服务下线的方法)。所以说一个服务如果没有心跳了,可能需要定时任务60秒+心跳时间90秒+过期判断90s,也许要4分钟以上,才能感知一个服务下线了,再加上客户端同步的间隔时间,时间就会更长。
服务自我保护机制
下面看一下eureka server自我保护机制。
场景
如果有20个服务实例,在1分钟以内,只有8个服务保持了心跳,那么eureka server会将剩余的12个没有心跳的服务实例全部摘除吗?其实不是的,有可能是由于eureka server自己的机器所在的网络故障了,导致那些服务心跳发送不过来,导致eureka server一直没有更新心跳的时间。
进入自我保护机制以后,就不会摘除任何实例了。
还是看上面一节的evict方法,第一行就有一个判断:
1 | // 是否允许主动删除实例,和自我保护机制有关 |
这个代码命名其实也是非常奇怪的,你光看名字,永远也想不到isLeaseExpirationEnabled方法里会包含自我保护机制的触发代码。
1 | public boolean isLeaseExpirationEnabled() { |
源码分析
isLeaseExpirationEnabled方法判断自我保护机制开启
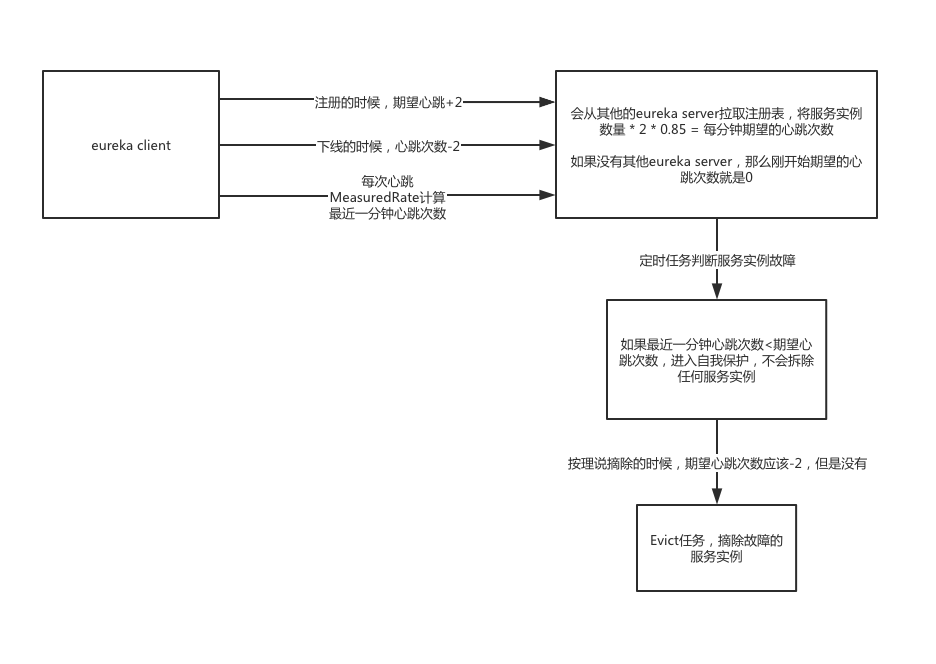
在evict服务故障的定时任务中,有个isLeaseExpirationEnabled方法会判断上一分钟的心跳次数是否小于期望的一分钟内心跳次数,如果小于,那么不会清理服务实例。
如何计算期望的一分钟心跳次数
numberOfRenewsPerMinThreshold的值是如何设定的?
EurekaBootStrap是启动初始化的类,有一行registry.openForTraffic(开启故障检查)的代码,完成了numberOfRenewsPerMinThreshold的初始化。
首先调用sync方法,从相邻的eureka server节点拷贝注册表(调用服务实例列表后注册到本地),拿到服务实例的数量。服务实例数量 * 2 * getRenewalPercentThreshold(0.85)。得到numberOfRenewsPerMinThreshold。1
2
3
4
5
6// Renewals happen every 30 seconds and for a minute it should be a factor of 2.
// 如果心跳时间间隔修改了怎么办?这里不应该硬编码,应该用心跳间隔时间作来计算。
this.expectedNumberOfRenewsPerMin = count * 2;
// count * 2 * 0.85
this.numberOfRenewsPerMinThreshold =
(int) (this.expectedNumberOfRenewsPerMin * serverConfig.getRenewalPercentThreshold());实际上这里的*2的操作,是很迷的一种写法,首先他这个地方硬编码了。然后他想表达的意思是,如果有10个实例,那么就在1分钟以内,要收到20次心跳,因为30秒一次心跳嘛。可是如果用户自己修改了心跳的间隔2时间,那这个地方不就BUG了吗?
在注册、下线、故障的时候,肯定也会更新值,这里有个小技巧,我们要查找一个变量在哪些地方赋值过。可以在IDEA里按快捷
ALT+F7,在看源码的时候非常有用,如截图所示,在前边有红色一根笔的小图标,可以看得出来是写操作,绿色一本书是读操作。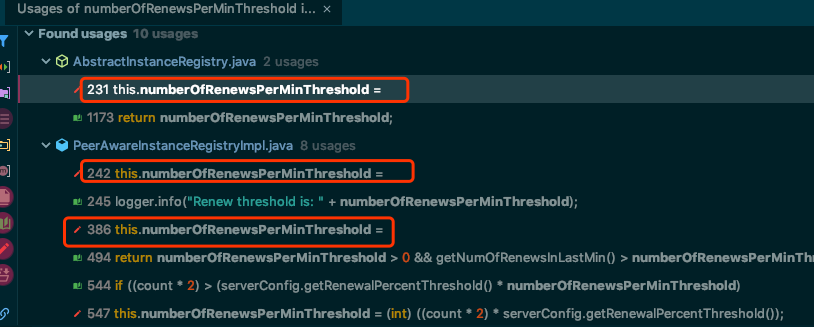
AbstractInstanceRegistry.register方法中,这里再一次做了硬编码,新注册一个实例后,每分钟期望的心跳次数就会+ 2。一样的,下线就是-2。那么故障的时候有更新这个值吗?我反正是没有找到,直接调用internalCancel方法不会去更新这个值,所以这应该是一个BUG!!!因为如果都是因为故障下线的,这个期望的心跳值并没有更新,实际的心跳次数又变少。那么每次在清除实例的时候,可能导致快速的开启了自我保护机制,而不再去清理任何的实例了。1
2
3this.expectedNumberOfRenewsPerMin = this.expectedNumberOfRenewsPerMin + 2;
this.numberOfRenewsPerMinThreshold =
(int) (this.expectedNumberOfRenewsPerMin * serverConfig.getRenewalPercentThreshold());定时更新,根据
ALT+F7的方式,PeerAwareInstanceRegistryImpl初始化的时候,启了定时调度任务,默认是15分钟执行一次。1
2
3
4
5
6
7
8
9private void scheduleRenewalThresholdUpdateTask() {
timer.schedule(new TimerTask() {
public void run() {
updateRenewalThreshold();
}
}, serverConfig.getRenewalThresholdUpdateIntervalMs(),
serverConfig.getRenewalThresholdUpdateIntervalMs());
}在updateRenewalThreshold任务中,从别的服务同步并合并注册表。然后计算出一个服务实例的数量。如果拉取到的服务实例数量,大于本地的期望的服务实例数量*0.85。**我觉得这里是不是写错了,numberOfRenewsPerMinThreshold本来就是count*2*0.85,这里判断再*0.85???**接着再次计算了一下服务实例列表的count,count * 2 * 0.85。这个代码也是骚的很,刚计算了
expectedNumberOfRenewsPerMin=count * 2,下面却不用这个变量,又写了一遍。1
2
3
4
5
6
7
8
9synchronized (lock) {
// Update threshold only if the threshold is greater than the
// current expected threshold of if the self preservation is disabled.
if ((count * 2) > (serverConfig.getRenewalPercentThreshold() * numberOfRenewsPerMinThreshold)
|| (!this.isSelfPreservationModeEnabled())) {
this.expectedNumberOfRenewsPerMin = count * 2;
this.numberOfRenewsPerMinThreshold = (int) ((count * 2) * serverConfig.getRenewalPercentThreshold());
}
}
实际的上一分钟心跳次数是如何计算的?
回到前面判断是否开启自我保护的代码,实际的上一分钟心跳次数getNumOfRenewsInLastMin(),用到了MeasuredRate,我们可以用ALT + F7去找increment方法的调用处,直接定位到了renew(心跳)的方法。
1 | // 实际的上一分钟心跳次数 + 1 |
自我保护机制的触发
如果上一分钟,实际的心跳次数少于了期望的心跳次数,那么就会开启自我保护机制,不允许摘除任何服务实例。此时认为自己的eureka server出现网络故障,大量的服务实例无法发送心跳过来。
总结
本文系统讲解了技术要点,通过学习掌握核心知识和实践方法。