负载均衡 服务注册 ,就是在分布式系统中,将注册的ip和端口号等信息告诉注册中心。
服务发现 就是客户端去注册中心获取服务列表,知道每一个服务实例的ip和端口是什么。
负载均衡 就是在拿到了这个服务列表以后,从中要选取一个实例来进行调用,这里就需要用到负载均衡算法。在Spring Cloud中,Ribbon就是做负载均衡用的一个组件,在这边叫做客户端负载均衡。具体的概念咋回事和如何使用我这里就不介绍了,网上文章很多,用过SpringCloud的人也应该都用过,下面开始进入源码探索。
Spring Cloud Ribbon Spring Cloud Ribbon组件,也是基于Netflix Ribbon做的封装。
Ribbon包含几个核心组件:
IRule:负载均衡规则组件,轮询,随机,权重等。
IPing: 用于检测服务是否存活,剔除宕机的服务。
ServerList: 针对不同的注册中心,有不同的实现类,例如ConsulServerList,NacosServiceList,ZookeeperServerList以及eureka的DomainExtractingServerList。
ILoadBalancer:负载均衡器,选择服务用,包含了IRule、IPing和ServerList。
LoadBalancerClient: 这是SpringCloud二次封装的一层组件,基于以上组件进行服务列表更新,过滤,选择并发起http调用。
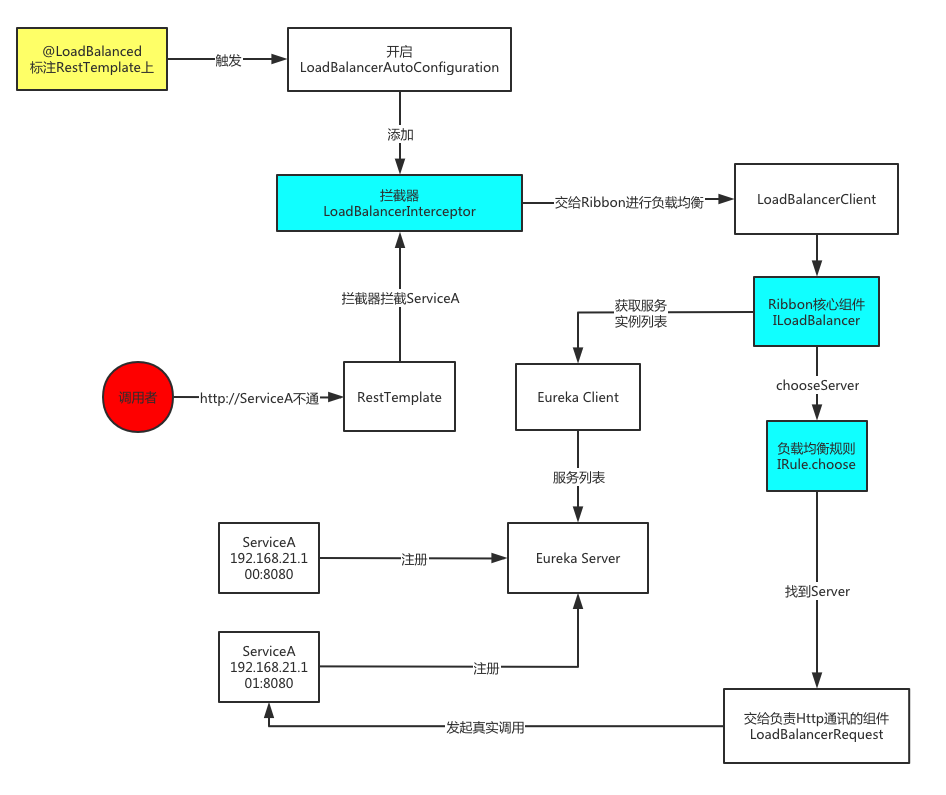
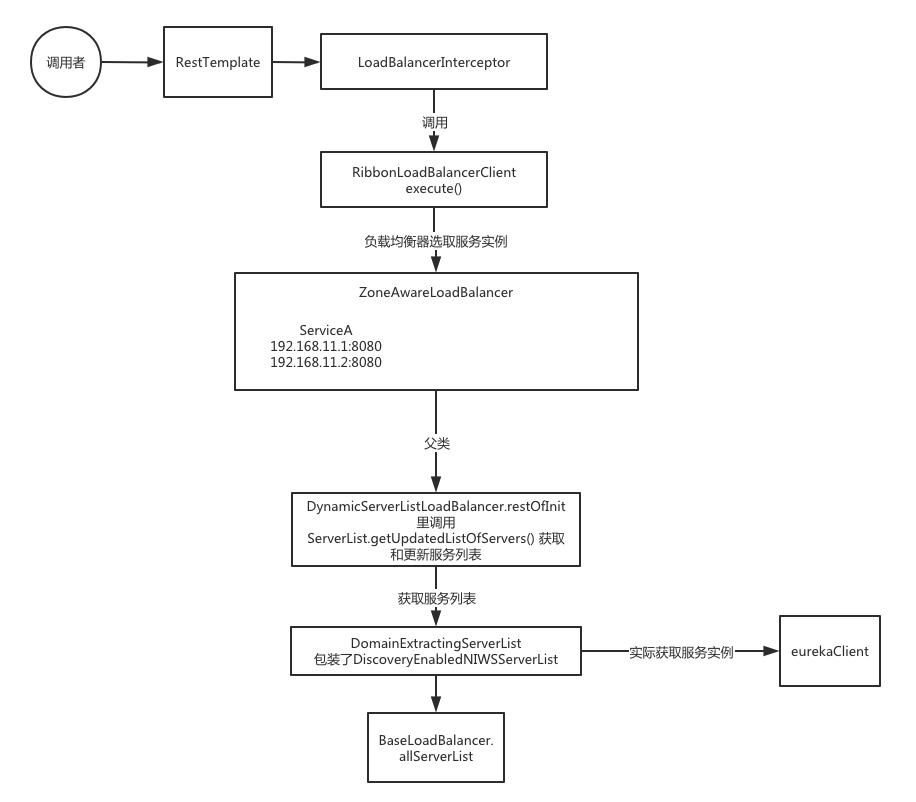
大体流程如下图所示:
自动装配LoadBalancerAutoConfiguration
在自动配置类中,会为RestTemplate添加拦截器LoadBalancerInterceptor
调用请求后,拦截器中获取host,并在LoadBalancerClient中对host信息进行转换,得到真正的服务器地址。
LoadBalancerClient中从Eureka client得到服务实例列表,然后通过包含了负载均衡规则IRule,选出要发起调用的server。
交给负责Http通讯的组件LoadBalancerRequest执行真正的http请求。
RestTemplate如何拥有负载均衡的能力 1 2 3 4 5 @LoadBalanced @Bean public RestTemplate restTemplate () { return new RestTemplate (); }
@LoadBalanced的源码: 标记RestTemplate被配置为使用LoadBalancerClient。
1 Annotation to mark a RestTemplate bean to be configured to use a LoadBalancerClient
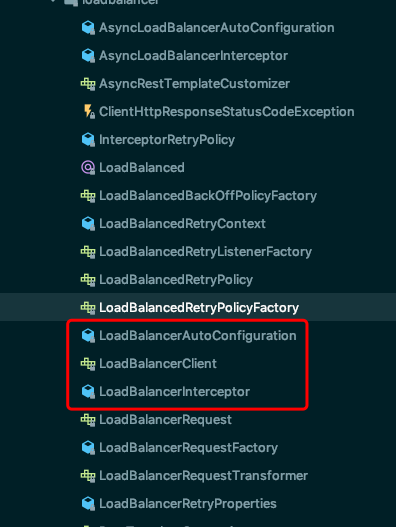
定位在这个注解所在的jar包,可以发现有如下的类:
根据SpringBoot的命名习惯,自动装配的类一般都是XXXAutoConfiguration,所以我们应该重点关注LoadBalancerAutoConfiguration这个类,进去看看,我省略掉部分代码,找到我们最应该关注的部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 @Configuration @ConditionalOnClass(RestTemplate.class) @ConditionalOnBean(LoadBalancerClient.class) @EnableConfigurationProperties(LoadBalancerRetryProperties.class) public class LoadBalancerAutoConfiguration { @LoadBalanced @Autowired(required = false) private List<RestTemplate> restTemplates = Collections.emptyList(); .....省略部分代码 @Configuration @ConditionalOnMissingClass("org.springframework.retry.support.RetryTemplate") static class LoadBalancerInterceptorConfig { @Bean public LoadBalancerInterceptor ribbonInterceptor ( LoadBalancerClient loadBalancerClient, LoadBalancerRequestFactory requestFactory) { return new LoadBalancerInterceptor (loadBalancerClient, requestFactory); } @Bean @ConditionalOnMissingBean public RestTemplateCustomizer restTemplateCustomizer ( final LoadBalancerInterceptor loadBalancerInterceptor) { return new RestTemplateCustomizer () { @Override public void customize (RestTemplate restTemplate) { List<ClientHttpRequestInterceptor> list = new ArrayList <>( restTemplate.getInterceptors()); list.add(loadBalancerInterceptor); restTemplate.setInterceptors(list); } }; } } ....省略部分代码 }
可以看到,这里给系统里的RestTemplate添加了拦截器,LoadBalancerInterceptor。在声明了LoadBalancerInterceptor后,用RestTemplateCustomizer定制化了拦截器restTemplate.setInterceptors(list);。
去LoadBalancerInterceptor看看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor { private LoadBalancerClient loadBalancer; private LoadBalancerRequestFactory requestFactory; public LoadBalancerInterceptor (LoadBalancerClient loadBalancer, LoadBalancerRequestFactory requestFactory) { this .loadBalancer = loadBalancer; this .requestFactory = requestFactory; } public LoadBalancerInterceptor (LoadBalancerClient loadBalancer) { this (loadBalancer, new LoadBalancerRequestFactory (loadBalancer)); } @Override public ClientHttpResponse intercept (final HttpRequest request, final byte [] body, final ClientHttpRequestExecution execution) throws IOException { final URI originalUri = request.getURI(); String serviceName = originalUri.getHost(); Assert.state(serviceName != null , "Request URI does not contain a valid hostname: " + originalUri); return this .loadBalancer.execute(serviceName, requestFactory.createRequest(request, body, execution)); } }
这个源码打开一看,我们一下就明朗了,原来SpringCloud是这样通过拦截器实现了restTeplate.getForObject(“http://serviceA/hello “) 到restTeplate.getForObject(“http://192.168.21.100:8080/hello")的转换。
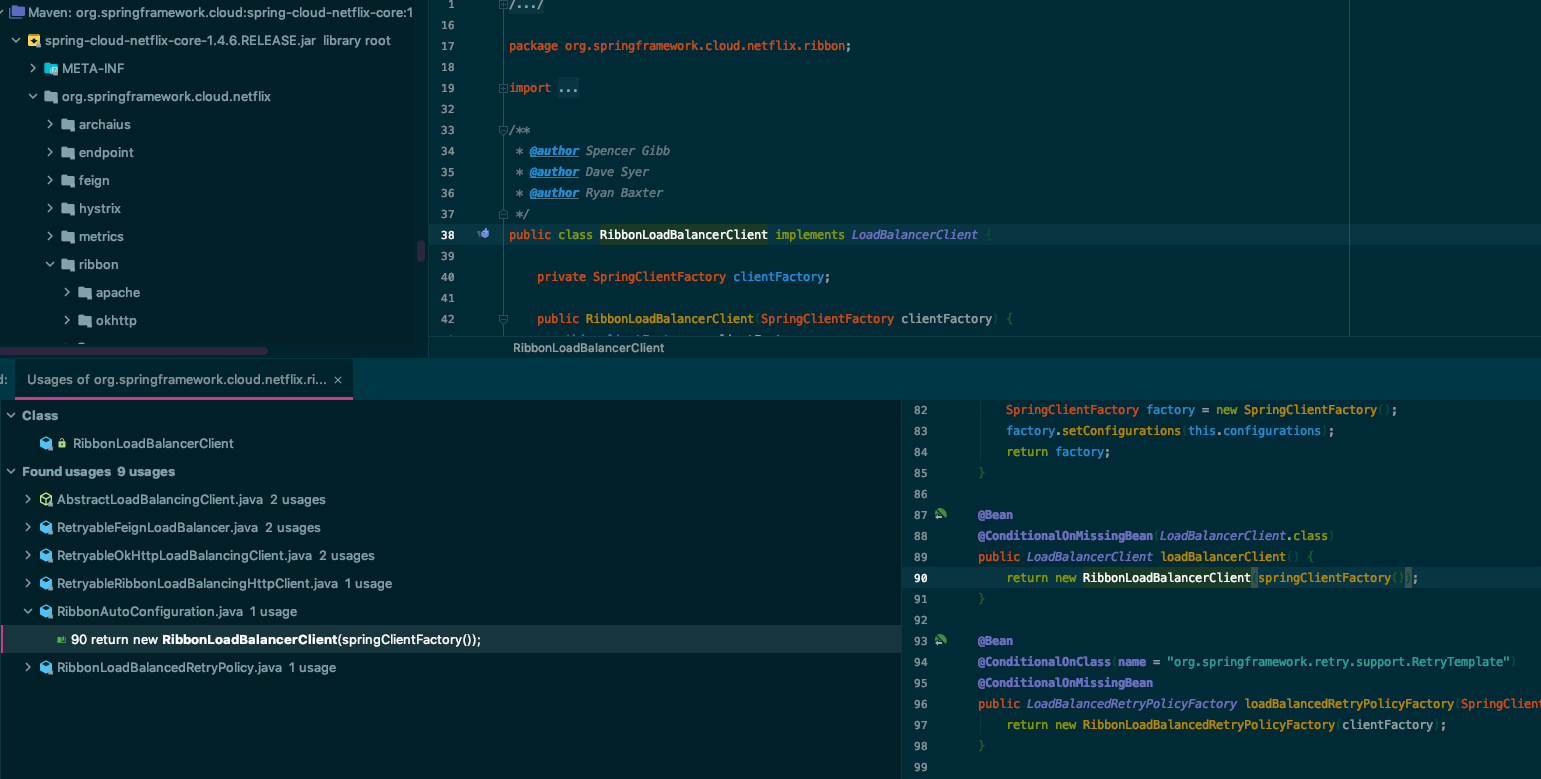
在RibbonLoadBalancerClient的类上按option(alt) + F7,可以迅速的找到在哪里声明创建的这个类的实例,如下图所示,也就是在RibbonAutoConfiguration类里。
接着看一下RibbonLoadBalancerClient的execute方法具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Override public <T> T execute (String serviceId, LoadBalancerRequest<T> request) throws IOException { ILoadBalancer loadBalancer = getLoadBalancer(serviceId); Server server = getServer(loadBalancer); if (server == null ) { throw new IllegalStateException ("No instances available for " + serviceId); } RibbonServer ribbonServer = new RibbonServer (serviceId, server, isSecure(server, serviceId), serverIntrospector(serviceId).getMetadata(server)); return execute(serviceId, ribbonServer, request); } .....省略部分代码 protected Server getServer (ILoadBalancer loadBalancer) { if (loadBalancer == null ) { return null ; } return loadBalancer.chooseServer("default" ); }
负载均衡器ILoadBalancer 那么看到上面有个ILoadBalancer,ILoadBalancer维护了一份服务列表,并提供了过滤服务和用负载均衡选择server等功能。这个ILoadBalancer在SpringCloud中默认是用的什么实现呢,这里的实例是用SpringClientFactory.getLoadBalancer方法获取的,**这个SpringClientFactory是SpringCloud对Ribbon的一层封装,为每一个服务都创建了一个Spring ApplicationContext,每一个服务都有自己的client,load balancer 和 client configuration实例。**这个SpringClientFactory非常重要,它是为每一个服务指定不同配置的基础例如不同的服务采用不同的负载均衡规则,就是通过这个机制实现的。
在SpringClientFactory.getLoadBalancer方法里,调用了getInstance(name, ILoadBalancer.class);跟到代码里去看是如何获取实例的,最后跟到父类里,发现是用map维护了服务和上下文的对应关系,serviceA -> AnnotationConfigApplicationContext。
1 2 3 4 5 6 7 8 9 10 11 private Map<String, AnnotationConfigApplicationContext> contexts = new ConcurrentHashMap <>();protected AnnotationConfigApplicationContext getContext (String name) { if (!this .contexts.containsKey(name)) { synchronized (this .contexts) { if (!this .contexts.containsKey(name)) { this .contexts.put(name, createContext(name)); } } } return this .contexts.get(name); }
那么这个ILoadBalancer的实例究竟是在哪里创建的呢?还是老办法,option + F7,去找一个叫XXXConfiguration的类,于是在RibbonClientConfiguration的类里,发现了Bean的定义:
1 2 3 4 5 6 7 8 9 10 11 12 @Bean @ConditionalOnMissingBean public ILoadBalancer ribbonLoadBalancer (IClientConfig config, ServerList<Server> serverList, ServerListFilter<Server> serverListFilter, IRule rule, IPing ping, ServerListUpdater serverListUpdater) { if (this .propertiesFactory.isSet(ILoadBalancer.class, name)) { return this .propertiesFactory.get(ILoadBalancer.class, config, name); } return new ZoneAwareLoadBalancer <>(config, rule, ping, serverList, serverListFilter, serverListUpdater); }
默认是使用ZoneAwareLoadBalancer ,父类是:DynamicServerListLoadBalancer,再往上的父类是BaseLoadBalancer。
这里多说一句,其实RibbonClientConfiguration的加载,是在NamedContextFactory.createContext里加载的,而且优先级是最低的,具体可以看本文最后一节引用文章,现在不必细究,等把整体流程了解的差不多以后,再去看这种细节问题。
Ribbon如何获取到服务列表 在ZoneAwareLoadBalancer中,并没有找到和服务列表相关的代码,去父类的构造方法看下,调用了restOfInit方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void restOfInit (IClientConfig clientConfig) { boolean primeConnection = this .isEnablePrimingConnections(); this .setEnablePrimingConnections(false ); enableAndInitLearnNewServersFeature(); updateListOfServers(); if (primeConnection && this .getPrimeConnections() != null ) { this .getPrimeConnections() .primeConnections(getReachableServers()); } this .setEnablePrimingConnections(primeConnection); LOGGER.info("DynamicServerListLoadBalancer for client {} initialized: {}" , clientConfig.getClientName(), this .toString()); }
看来serverListImpl,也就是ServerList就是获取服务列表的关键。那么这个ServerList是在构造方法里传入的,所以回到ZoneAwareLoadBalancer的Bean定义的地方,可以看到他是通过依赖注入获取到的。
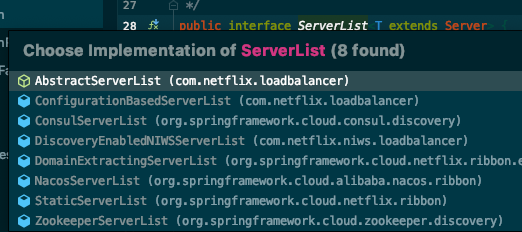
通过IDEA看一下接口有哪些实现类:
可以看到,针对不同的注册中心,有不同的实现类,例如ConsulServerList,NacosServiceList,ZookeeperServerList以及在spring cloud eureka包下面的DomainExtractingServerList。
由此可以断定,SpringCloud在和Ribbon和Eureka整合的时候,一定使用了DomainExtractingServerList这个类。更进一步的,找到了DomainExtractingServerList创建的地方,发现他又是包装了一层DiscoveryEnabledNIWSServerList,这个DiscoveryEnabledNIWSServerList是com.netflix.niws.loadbalancer;包下面的,在ribbon-eureka.jar里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Bean @ConditionalOnMissingBean public ServerList<?> ribbonServerList(IClientConfig config, Provider<EurekaClient> eurekaClientProvider) { if (this .propertiesFactory.isSet(ServerList.class, serviceId)) { return this .propertiesFactory.get(ServerList.class, config, serviceId); } DiscoveryEnabledNIWSServerList discoveryServerList = new DiscoveryEnabledNIWSServerList ( config, eurekaClientProvider); DomainExtractingServerList serverList = new DomainExtractingServerList ( discoveryServerList, config, this .approximateZoneFromHostname); return serverList; }
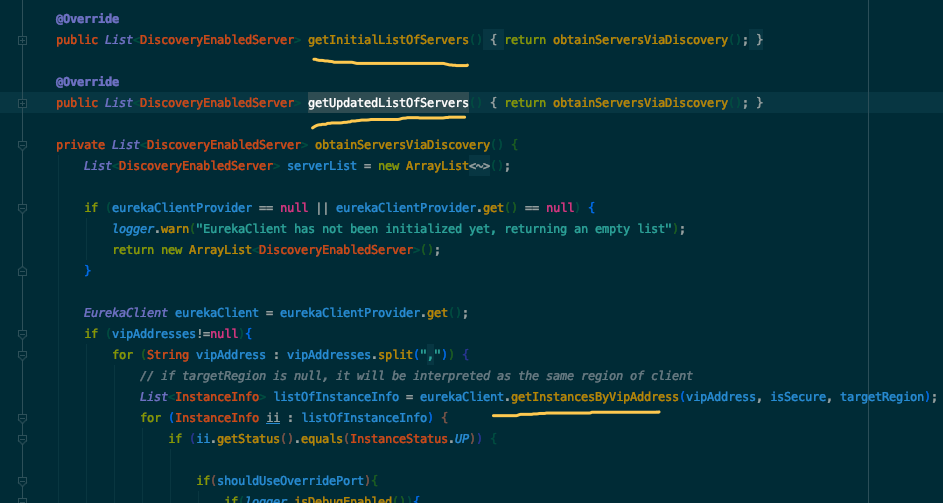
看下面截图是DiscoveryEnabledNIWSServerList的getInitialListOfServers和getUpdatedListOfServers方法,在这里看到了前面熟悉的eurekaClient,通过eurekaClient获取到了实例列表,并且转成了List返回,我们在用IDEA分析源码的时候,真的是非常的方便,可以通过查看类或者方法的引用,来找到创建或者使用的代码。也可以很方便的通过继承关系查看,就找到可能的具体的实现。
最后,将拿到的服务列表存入了成员变量allServerList中。
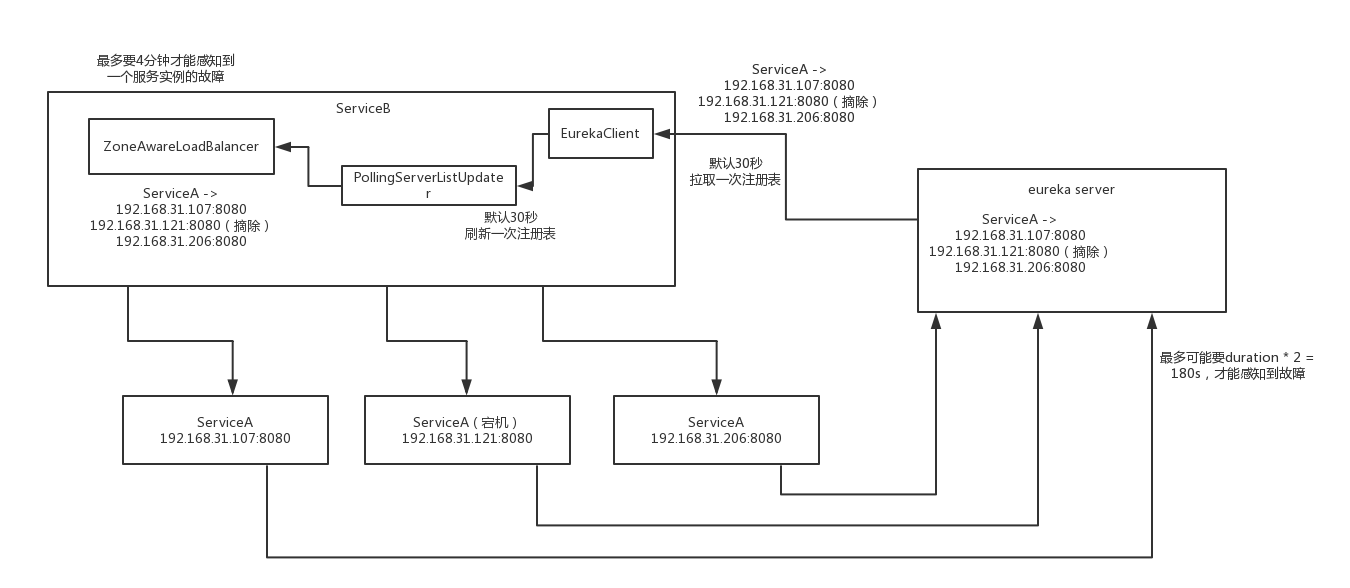
已经找到了更新服务列表的地方,那么他是什么时候去更新的呢,实际上在restOfInit方法调用的enableAndInitLearnNewServersFeature方法里,就调用了一个更新器:serverListUpdater,他会定时去更新,在构造方法里,构造了PollingServerListUpdater的实例,他是在启动1秒后,每隔30秒就会执行一次,去从eureka client里将服务列表定时同步到LoadBalancer的allServerList中。
1 2 3 4 5 6 public void enableAndInitLearnNewServersFeature () { LOGGER.info("Using serverListUpdater {}" , serverListUpdater.getClass().getSimpleName()); serverListUpdater.start(updateAction); }
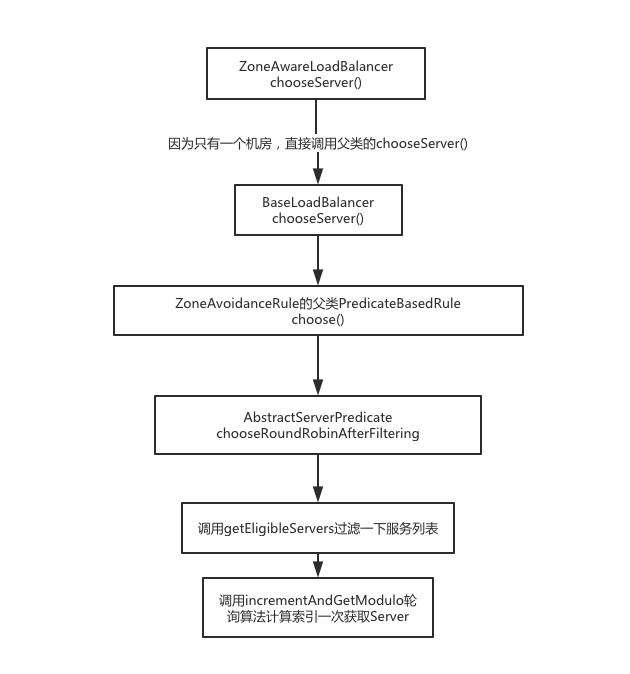
负载均衡算法如何选择一个server 前面有提到,在获取到负载均衡器(ILoadBalancer)后,就会调用chooseServer方法去选择一个server,看了眼他的逻辑,对每个机房都搞了个LoadBalancer,最后还是调用的BaseLoadBalancer.chooseServer方法,也就是父类的chooseServer方法,咱们在这里,就找到了rule.choose(key)的调用,所以接下来,我们就重点关注一下rule是哪里来的,他的默认实现又是什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public Server chooseServer (Object key) { if (counter == null ) { counter = createCounter(); } counter.increment(); if (rule == null ) { return null ; } else { try { return rule.choose(key); } catch (Exception e) { logger.warn("LoadBalancer [{}]: Error choosing server for key {}" , name, key, e); return null ; } } }
在ZoneAwareLoadBalancer的定义类里,也就是RibbonClientConfiguration里,也声明了IRule的Bean。
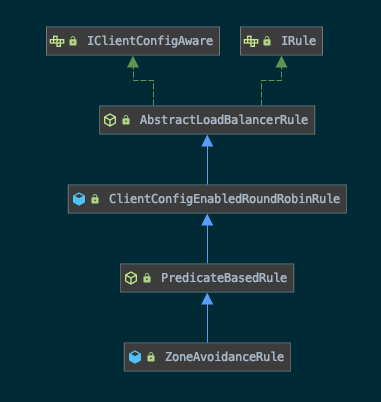
1 2 3 4 5 6 7 8 9 10 11 @Bean @ConditionalOnMissingBean public IRule ribbonRule (IClientConfig config) { if (this .propertiesFactory.isSet(IRule.class, name)) { return this .propertiesFactory.get(IRule.class, config, name); } ZoneAvoidanceRule rule = new ZoneAvoidanceRule (); rule.initWithNiwsConfig(config); return rule; }
那么在ZoneAvoidanceRule里,并没有找到choose方法,看一眼他的层级结构,choose方法在父类PredicateBasedRule里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public abstract AbstractServerPredicate getPredicate () ;@Override public Server choose (Object key) { ILoadBalancer lb = getLoadBalancer(); Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key); if (server.isPresent()) { return server.get(); } else { return null ; } }
getPredicate().chooseRoundRobinAfterFiltering,先过滤后再用轮询算法选择一个Server。这个具体算法可以在incrementAndGetModulo里找到,算出一个索引值,然后去List里取一个server。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public Optional<Server> chooseRoundRobinAfterFiltering (List<Server> servers, Object loadBalancerKey) { List<Server> eligible = getEligibleServers(servers, loadBalancerKey); if (eligible.size() == 0 ) { return Optional.absent(); } return Optional.of(eligible.get(incrementAndGetModulo(eligible.size()))); } private int incrementAndGetModulo (int modulo) { for (;;) { int current = nextIndex.get(); int next = (current + 1 ) % modulo; if (nextIndex.compareAndSet(current, next) && current < modulo) return current; } }
在这里说一句题外话,其实在工作中,这个地方我们可以大做文章,比如编写自己的Rule,实现自己的负责均衡算法。也可以利用getEligibleServers的过滤服务实例机制,去实现自己Predicate,从而实现一些灰度发布等操作。关于SpringCloud的灰度发布,可参考开源框架Nepxion Discovery:https://github.com/Nepxion/Discovery
拿到server后如何发起真正的请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Override public <T> T execute (String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest<T> request) throws IOException { Server server = null ; if (serviceInstance instanceof RibbonServer) { server = ((RibbonServer)serviceInstance).getServer(); } if (server == null ) { throw new IllegalStateException ("No instances available for " + serviceId); } RibbonLoadBalancerContext context = this .clientFactory .getLoadBalancerContext(serviceId); RibbonStatsRecorder statsRecorder = new RibbonStatsRecorder (context, server); try { T returnVal = request.apply(serviceInstance); .....
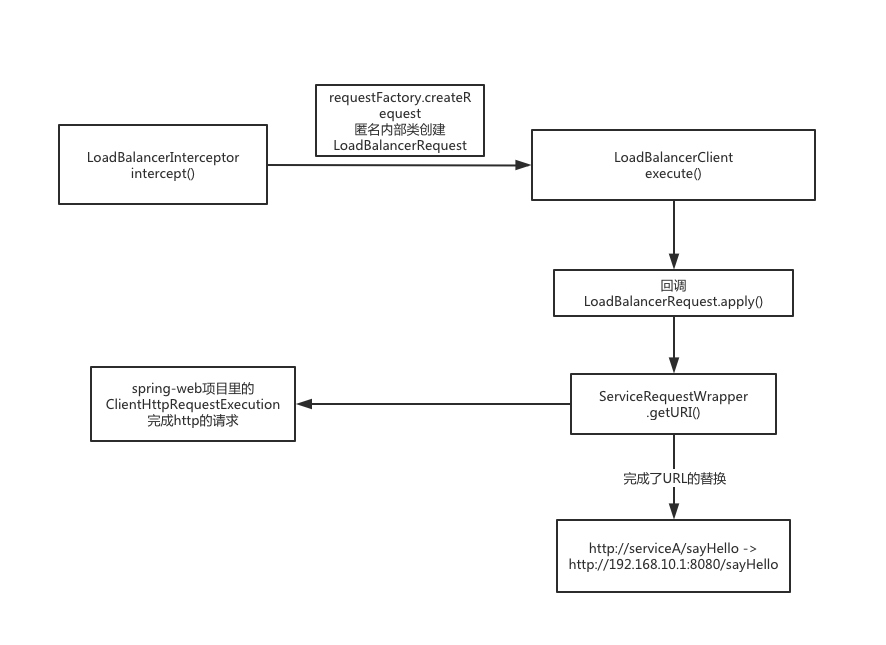
在选择到服务实例以后,RibbonLoadBalancerClient.execute()就要发起真正的调用了。用了一个回调,将被请求的服务器信息当作参数穿进去,完成了http的请求。
1 T returnVal = request.apply(serviceInstance);
所以回到LoadBalancerInterceptor类里,request是一个匿名内部类,在里面对request和服务实例进行了包装,将具体执行交给了ClientHttpRequestExecution。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 requestFactory.createRequest(request, body, execution) public LoadBalancerRequest<ClientHttpResponse> createRequest (final HttpRequest request, final byte [] body, final ClientHttpRequestExecution execution) { return new LoadBalancerRequest <ClientHttpResponse>() { @Override public ClientHttpResponse apply (final ServiceInstance instance) throws Exception { HttpRequest serviceRequest = new ServiceRequestWrapper (request, instance, loadBalancer); if (transformers != null ) { for (LoadBalancerRequestTransformer transformer : transformers) { serviceRequest = transformer.transformRequest(serviceRequest, instance); } } return execution.execute(serviceRequest, body); } }; }
到了ClientHttpRequestExecution里面,其实已经到了spring-web的类里了,spring-web从ServiceRequestWrapper获取到真正的请求URL地址,发起了http请求。所以spring-web的源码,这里就不再去看了,但是需要关注ServiceRequestWrapper,ServiceRequestWrapper完成了对真实请求地址的转换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public class ServiceRequestWrapper extends HttpRequestWrapper { private final ServiceInstance instance; private final LoadBalancerClient loadBalancer; public ServiceRequestWrapper (HttpRequest request, ServiceInstance instance, LoadBalancerClient loadBalancer) { super (request); this .instance = instance; this .loadBalancer = loadBalancer; } @Override public URI getURI () { URI uri = this .loadBalancer.reconstructURI( this .instance, getRequest().getURI()); return uri; } } @Override public URI reconstructURI (ServiceInstance instance, URI original) { Assert.notNull(instance, "instance can not be null" ); String serviceId = instance.getServiceId(); RibbonLoadBalancerContext context = this .clientFactory .getLoadBalancerContext(serviceId); URI uri; Server server; if (instance instanceof RibbonServer) { RibbonServer ribbonServer = (RibbonServer) instance; server = ribbonServer.getServer(); uri = updateToSecureConnectionIfNeeded(original, ribbonServer); } else { server = new Server (instance.getScheme(), instance.getHost(), instance.getPort()); IClientConfig clientConfig = clientFactory.getClientConfig(serviceId); ServerIntrospector serverIntrospector = serverIntrospector(serviceId); uri = updateToSecureConnectionIfNeeded(original, clientConfig, serverIntrospector, server); } return context.reconstructURIWithServer(server, uri); }
画个图总结下:
Ribbon IPing检查服务是否存活 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class NIWSDiscoveryPing extends AbstractLoadBalancerPing { public boolean isAlive (Server server) { boolean isAlive = true ; if (server!=null && server instanceof DiscoveryEnabledServer){ DiscoveryEnabledServer dServer = (DiscoveryEnabledServer)server; InstanceInfo instanceInfo = dServer.getInstanceInfo(); if (instanceInfo!=null ){ InstanceStatus status = instanceInfo.getStatus(); if (status!=null ){ isAlive = status.equals(InstanceStatus.UP); } } } return isAlive; } }
ribbon和eureka整合的时候,并不会真正的去检查服务是否存活,而是利用Discovery Client本来就会有定时更新服务列表的机制。
在BaseLoadBalancer类里,可以找到IPing的调用之处,他启动了一个定时任务
1 2 3 4 5 6 7 8 9 10 11 12 void setupPingTask () { if (canSkipPing()) { return ; } if (lbTimer != null ) { lbTimer.cancel(); } lbTimer = new ShutdownEnabledTimer ("NFLoadBalancer-PingTimer-" + name, true ); lbTimer.schedule(new PingTask (), 0 , pingIntervalSeconds * 1000 ); forceQuickPing(); }
默认是每隔30秒,就执行一次PingTask,task里用了一个读写锁完成了ping之后的服务实例列表计算,最后更新upServerList。
其他几种自带的负载均衡规则 BestAvailableRule:选择一个最小的并发请求的Server,逐个考察Server,如果Server被tripped了,则跳过。
AvailabilityFilteringRule:过滤掉那些一直连接失败的被标记为circuit tripped的后端Server,并过滤掉那些高并发的的后端Server或者使用一个AvailabilityPredicate来包含过滤server的逻辑,其实就就是检查status里记录的各个Server的运行状态。
ZoneAvoidanceRule:复合判断Server所在区域的性能和Server的可用性选择Server。
RandomRule:随机选择一个Server。
RoundRobinRule:轮询选择, 轮询index,选择index对应位置的Server。
RetryRule:对选定的负载均衡策略机上重试机制,在一个配置时间段内当选择Server不成功,则一直尝试使用subRule的方式选择一个可用的server。
ResponseTimeWeightedRule:作用同WeightedResponseTimeRule,二者作用是一样的,ResponseTimeWeightedRule后来改名为WeightedResponseTimeRule。
WeightedResponseTimeRule:根据响应时间分配一个weight(权重),响应时间越长,weight越小,被选中的可能性越低。
服务宕机后Ribbon多久能感知到 在和eureka结合使用的情况下,因为eureka server是靠心跳来摘除服务实例,那么他是需要duration * 2 =180秒,eureka client 从server同步(recentlyChangedQueue)默认是需要30秒,Ribbon从Eureka Client同步也是30秒,所以最多可能需要240秒,也就是4分钟才能知道一个服务已经宕机了,他是有可能访问到宕机的服务,不过SpringCloud是借用了Hystrix降级和熔断的机制来解决这个问题,一定次数错误后会屏蔽某个实例。
SpringCloud和Ribbon的全局配置和特定配置 这有篇文章写的比较清晰,说明了SpringCloud在读取Ribbon配置的时候是通过懒加载去读取配置的,也就是第一次发起调用的时候,才会通过NamedContextFactory.createContext去初始化@RibbonClients和@RibbonClient指定的配置。 但是@RibbonClients和@RibbonClient的配置被放入NamedContextFactory的configurations字段中,是在RibbonClientConfigurationRegistrar这个类里,结合源码看看文章,就很清楚了。
https://www.cnblogs.com/trust-freedom/p/11216280.html
总结 本文系统讲解了技术要点,通过学习掌握核心知识和实践方法。