Eureka源码解析 03:服务列表同步
eureka client全量抓取注册表
eureka client第一次启动的时候,会从eureka server端抓取全量的注册表,在本地进行缓存。后续每隔30秒从eureka server端抓取增量的注册表信息,和本地缓存进行合并。
先找到第一次抓取全量注册表的源码,没记错的话应该是在创建DiscoveryClient的构造方法里。就是下面这几行代码:
1 | if (clientConfig.shouldFetchRegistry() && !fetchRegistry(false)) { |
这个fetchRegistry方法,就是抓取注册表的方法。
1 | // DiscoveryClient.fetchRegistry() |
eureka server端处理抓取注册表的请求(多级缓存机制)
根据客户端请求的接口(GET ip:port/v2/apps),去服务端找对应的处理方法。是在ApplicationsResource.getContainers方法。
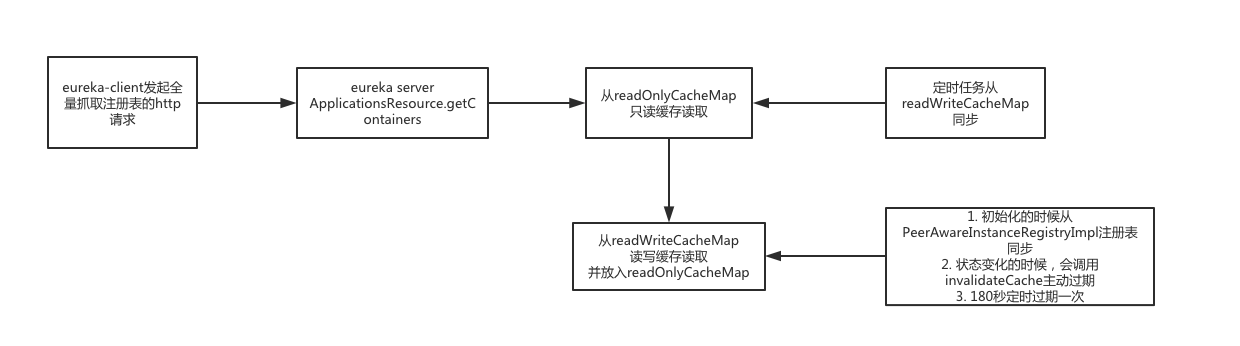
eureka server端,有一套多级缓存的机制,这里的cacheKey,就是缓存用的Key,然后下面就是从缓存读取数据的逻辑,注意这里的key是ALL_APPS。
1 | Key cacheKey = new Key(Key.EntityType.Application, |
eureka server的缓存,是基于ResponseCache这样的一个接口开发的。实现类是ResponseCacheImpl,看下它的get方法。
1 | @VisibleForTesting |
这里的条件useReadOnlyCache,是通过配置读取的。再跟进去看看源码,getValue方法里,看到有了2个map,做了两级缓存,分别是readOnlyCacheMap和readWriteCacheMap,readWriteCacheMap是基于Guava Cache封装的一个缓存,程序先从只读缓存里去读,如果没有的话,会从读写缓存里去读,还是没有的话,才会从registry的map里读。实际上在ResponseCacheImpl的构造方法里,就包含了readWriteCacheMap数据初始化的逻辑。
generatePayload方法中,从注册表中获取所有的Applications,通过ServerCodecs组件,将Applications对象序列化成一个json字符串,然后放入读写缓存(readWriteCacheMap)。接着,放入只读缓存中(readOnlyCacheMap)。
多级缓存过期机制
主动过期
有新的服务实例发生注册、下线、故障的时候,会刷新readWriteCacheMap。PeerAwareInstanceRegistryImpl的javadoc,说这个类会同步一些状态变化到其他节点,同时我们也看他也维护了注册表信息,并且注册的register方法也是在这里面,我们在register方法里,找到invalidateCache代码
1 | // invalidate cache |
这不就是调用responseCache的主动过期方法吗?之前注册的时候看不懂的逻辑,现在一切都明了。借助IDEA的快捷键,在invalidateCache方法上按option + F7,还能找到所有调用的方法,分别是:register、internalCancel、statusUpdate、deleteStatusOverride。
定时过期
被动过期在初始化缓存的时候就已经设置了过期属性,.expireAfterWrite(serverConfig.getResponseCacheAutoExpirationInSeconds(), TimeUnit.SECONDS),默认值是180秒。
被动过期
readOnlyCacheMap是在初始化的时候,设置了一个定时器,默认每隔30从readWriteCacheMap里对数据进行比对,如果数据不一致,就同步数据。
总结
所以说有服务注册、故障或者下线了,因为缓存的原因,其他客户端可能要30秒才能感知到。
增量抓取注册表
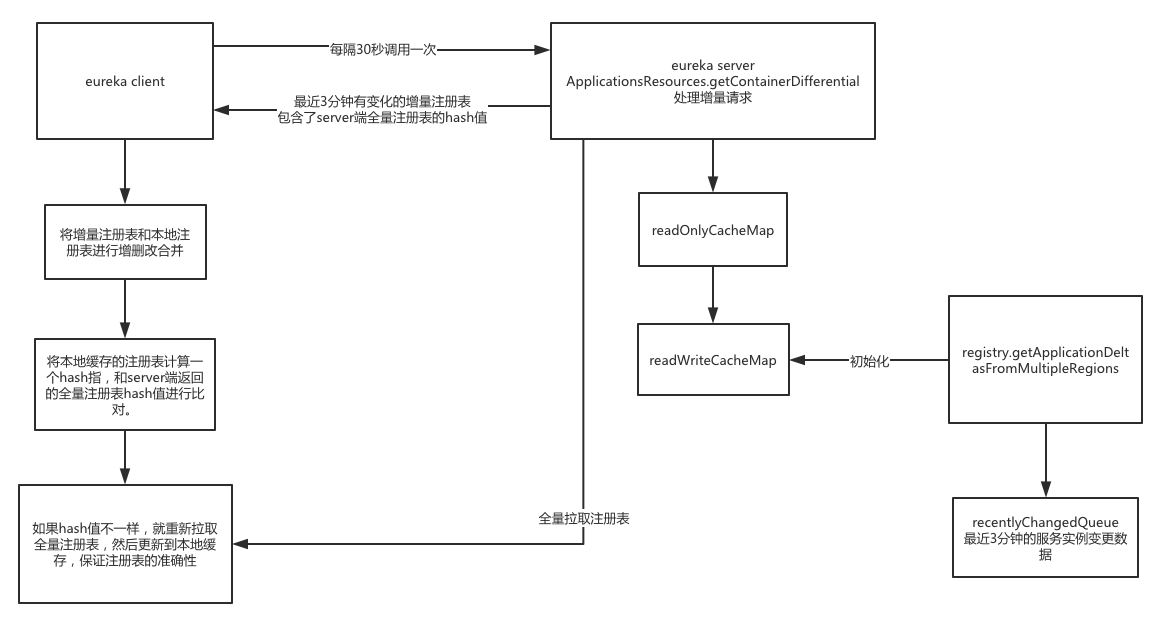
上面有说到,在eureka client初始化的时候,会全量的抓取一次注册表,然后在initScheduledTasks里启动了一个定时任务,每隔30秒会定时增量同步一次注册表的信息,具体的执行类叫做CacheRefreshThread。
- 定时任务,30秒一次
- 因为本地有缓存的Applications,所以走增量抓取的逻辑
- 走eurekaHttpClient的getDelta接口,
GET apps/delta - ApplicationsResources.getContainerDifferential处理增量请求
- 一样是走多级缓存机制,key是ALL_APPS_DELTA。后面就是一样了,唯一的区别就是因为key不一样,所以在generatePayload方法里,执行的逻辑不一样,这里不再用registry.getApplications()获取全量数据,而是用registry.getApplicationDeltasFromMultipleRegions(key.getRegions()));获取增量的注册表信息。
- 这儿有个recentlyChangedQueue,在状态变化的时候会往里边放数据,代表着最近有变化的服务实例,增量信息就是从这里边去抓取。在Registry初始化的时候有个定时任务,每隔30秒检查一次,这个队列里面的服务实例变更信息是否已经超过180秒了,如果超过会移除。所以这个队列里保留的其实是最近3分钟的服务实例变更数据。
- eureka client每隔30秒,去抓取增量注册表的时候,会拿到最近3分钟内有变化的服务实例的注册表。
- 抓取到的注册表和本地缓存的注册表进行合并,完成服务实例的增删改。updateDelta(delta);
- 对合并后的注册表计算一个hash值,之前返回的delta带了一个eureka server全量注册表的hash值。对这2个值进行对比,如果不一致,此时会从eureka server抓取全量的注册表到本地。
总结
亮点
- 如果要保存增量的最新数据变更,可以基于LinkedQueue将最新变更的数据放入这个queue中,然后用定时任务在队列超过一定时间的数据移除,保持这个队列中就是最近几分钟内变更的增量数据。
- 数据同步的hash值对:如果在分布式系统里,在不同的地方进行数据的同步,可以采用hash值的思想,从一个地方计算一个hash值,在另外一个地方也计算一个hash值,保证两个hash值是一样的,这样可以保证数据的准确性。