Java并发编程 02:同步机制
volatile
先说结论,volatile是非常常用的东西,他保证了可见性和有序性。这2个特性分别涉及了JVM的底层原理,最常用的场景,就是共享变量加volatile修饰,这样不同的线程来修改的时候,才能即时的识别到改变,比如标志位、开关等。
1 | /** |
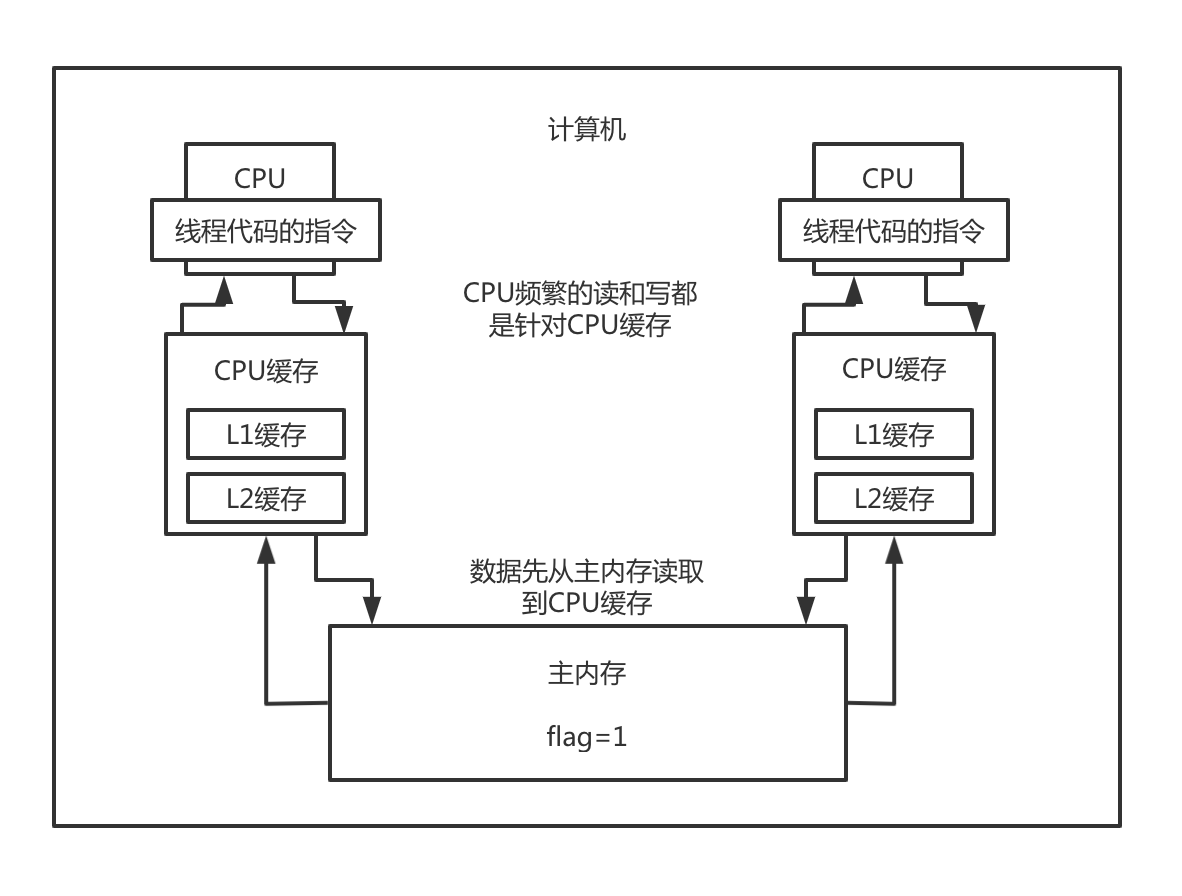
主内存以及cpu的多级缓存模型
先看下计算机CPU的多级缓存模型,为什么要讲这个,因为这个就是volatile的基本原理。
volatile的作用就是一个线程修改了一个变量的值以后,另外一个变量立马就能看到最新的值。
我们得先知道,为什么在不加volatile的情况下,它不一定能看到最新的值。
计算机如果频繁的跟主内存做交互的话,性能也是比较差的,所以CPU有自己的缓存,用来提升CPU计算的效率,我们买电脑,也会看到CPU参数里有L1,L2,L3缓存的。
然后CPU读写数据,会先从主内存读取到缓存中,然后频繁的读写,都是在缓存里操作的,缓存的数据会不定时的刷入到主内存中。
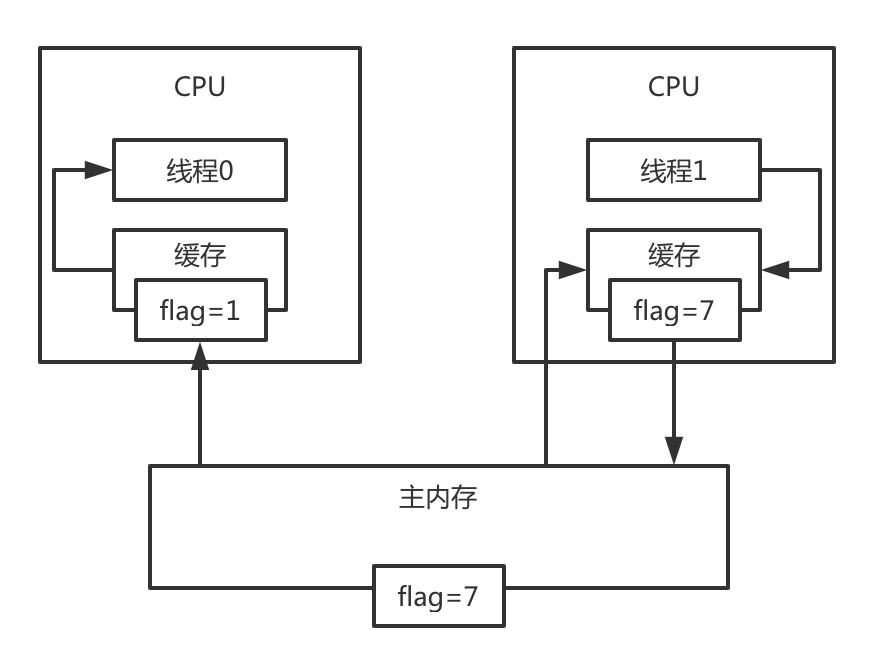
并发问题
那么这么设计有什么问题呢,在正常情况下是没有问题的,但是在多线程并发的情况下,就会有问题了,可能每个线程持有flag的值,是不一样的。
比如线程0先读取了falg=1,然后线程1写入了flag=7, 这时候主内存里已经是flag=7了,线程0和线程1看到flag的值,就是不一样的。
解决方法
最早的时候,有一个总线加锁的机制,有点类似于悲观锁,一个CPU读取了一个数据后,会通过一个总线,就对这块内存(数据)进行加锁,然后其他CPU就无法再读和写这个数据了,只有当这个CPU修改完成后,其他CPU就可以读到最新的数据,这个效率比较低下,基本成串行化执行了。
所以后面就有了MESI协议,缓存一致性协议。
在MESI缓存一致性协议的保证下,就能保证在多线程并发读写变量,及时感知到了。
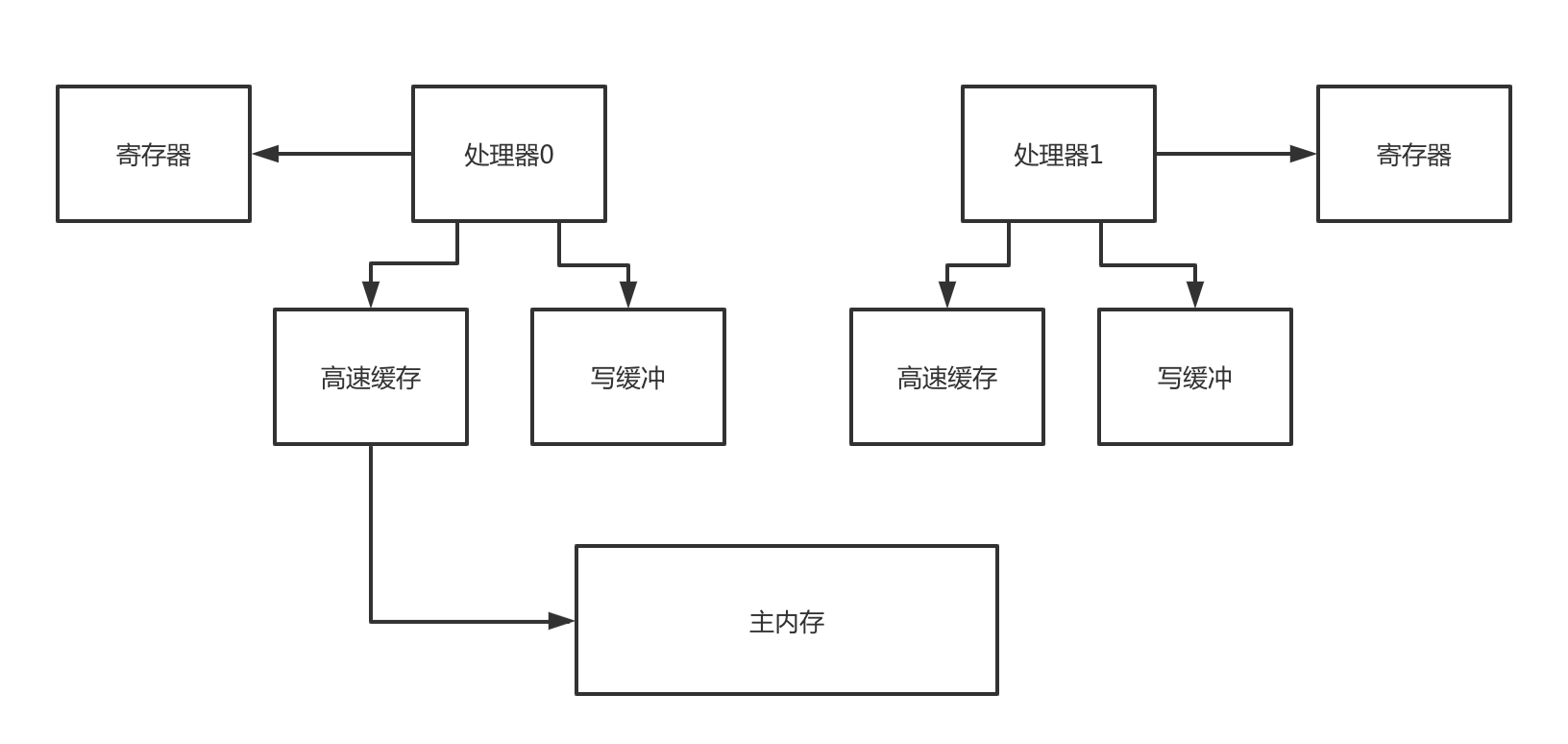
可见性涉及的硬件概念
寄存器
每个处理器都有自己的寄存器(register),所以多个处理器各自运行一个线程的时候,可能导致某个变量给放到寄存器里去,接着就会导致各个线程没法看到其他处理器寄存器里的变量的值修改了。
所以在寄存器这里,就有可能会导致变量副本的更新,无法被其他线程看到。
缓冲
一个处理器运行的线程对变量的写操作都是针对写缓冲来的(store buffer)并不是直接更新主内存,所以很可能导致一个线程更新了变量,但是仅仅是在写缓冲区里罢了,没有更新到主内存里去。
这个时候,其他处理器的线程是没法读到他的写缓冲区的变量值的,所以此时就是会有可见性的问题,这是第二个可见性发生的场景。
高速缓存
即使这个时候一个处理器的线程更新了写缓冲区之后,将更新同步到了自己的高速缓存里(cache,或者是主内存),然后还把这个更新通知给了其他的处理器,但是其他处理器可能就是把这个更新放到无效队列里去,没有更新他的高速缓存,此时其他处理器的线程从高速缓存里读数据的时候,读到的还是过时的旧值。
MESI
要实现可见性,其中一个方法就是MESI协议,这个协议有很多不同的实现,根据底层硬件的不同,实现方式也不同。
flush处理器缓存
flush处理器缓存,是把自己更新的值刷新到高速缓存里去(或者是主内存),因为必须要刷到高速缓存(或者是主内存)里,才有可能在后续通过一些特殊的机制让其他的处理器从自己的高速缓存(或者是主内存)里读取到更新的值。
除了flush以外,他还会发送一个消息到总线(bus),通知其他处理器,某个变量的值被他给修改了。
refresh处理器缓存
refresh处理器缓存,是指处理器中的线程在读取一个变量的值的时候,如果发现其他处理器的线程更新了变量的值,必须从其他处理器的高速缓存(或者是主内存)里,读取这个最新的值,更新到自己的高速缓存中。
所以为了保证可见性,在底层是通过MESI协议、flush处理器缓存和refresh处理器缓存,这一整套机制来保障的。
要记住,flush和refresh,这两个操作,flush是强制刷新数据到高速缓存(主内存),不要仅仅停留在写缓冲器里面;refresh,是从总线嗅探发现某个变量被修改,必须强制从其他处理器的高速缓存(或者主内存)加载变量的最新值到自己的高速缓存里去。
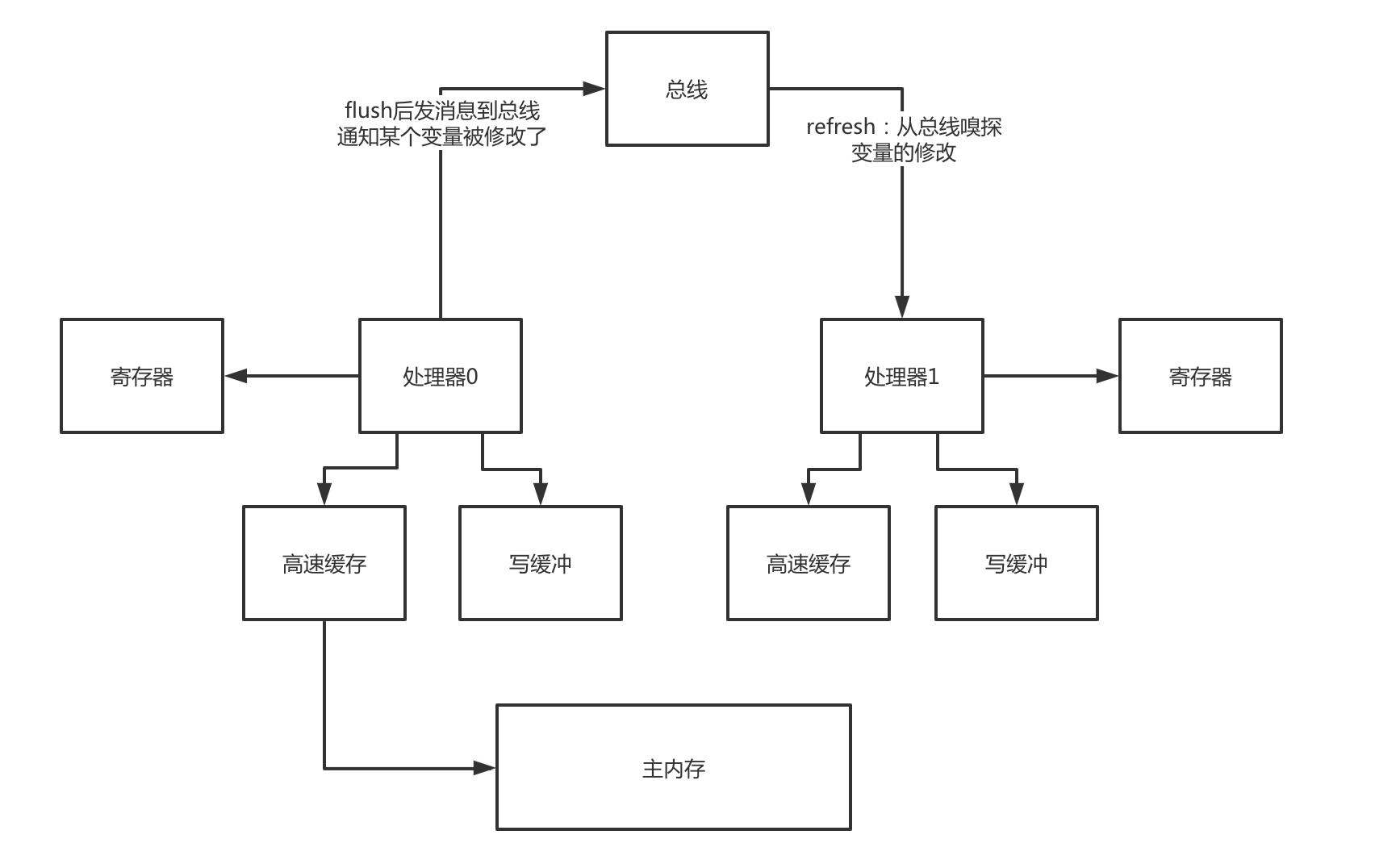
对一个变量加了volatile修饰之后,对这个变量的写操作,会执行flush处理器缓存,把数据刷到高速缓存(或者是主内存)中,然后对这个变量的读操作,会执行refresh处理器缓存,从其他处理器的高速缓存(或者是主内存)中,读取最新的值。
Java内存模型
Java内存模型跟CPU缓存模型是类似的,它是基于CPU模型来建立的Java内存模型,只是Java内存模型是标准化的,屏蔽了底层计算机和操作系统的区别。
在Java里,内存分线程工作内存和主内存,他们之间的读写,是用JVM底层的指令完成的。
- read(从主存读取)
- load(将主存读取到的值写入工作内存)
- use(从工作内存读取数据来计算)
- assign(将计算好的值重新赋值到工作内存中)
- store(将工作内存数据写入主存)
- write(将store过去的变量值赋值给主存中的变量)
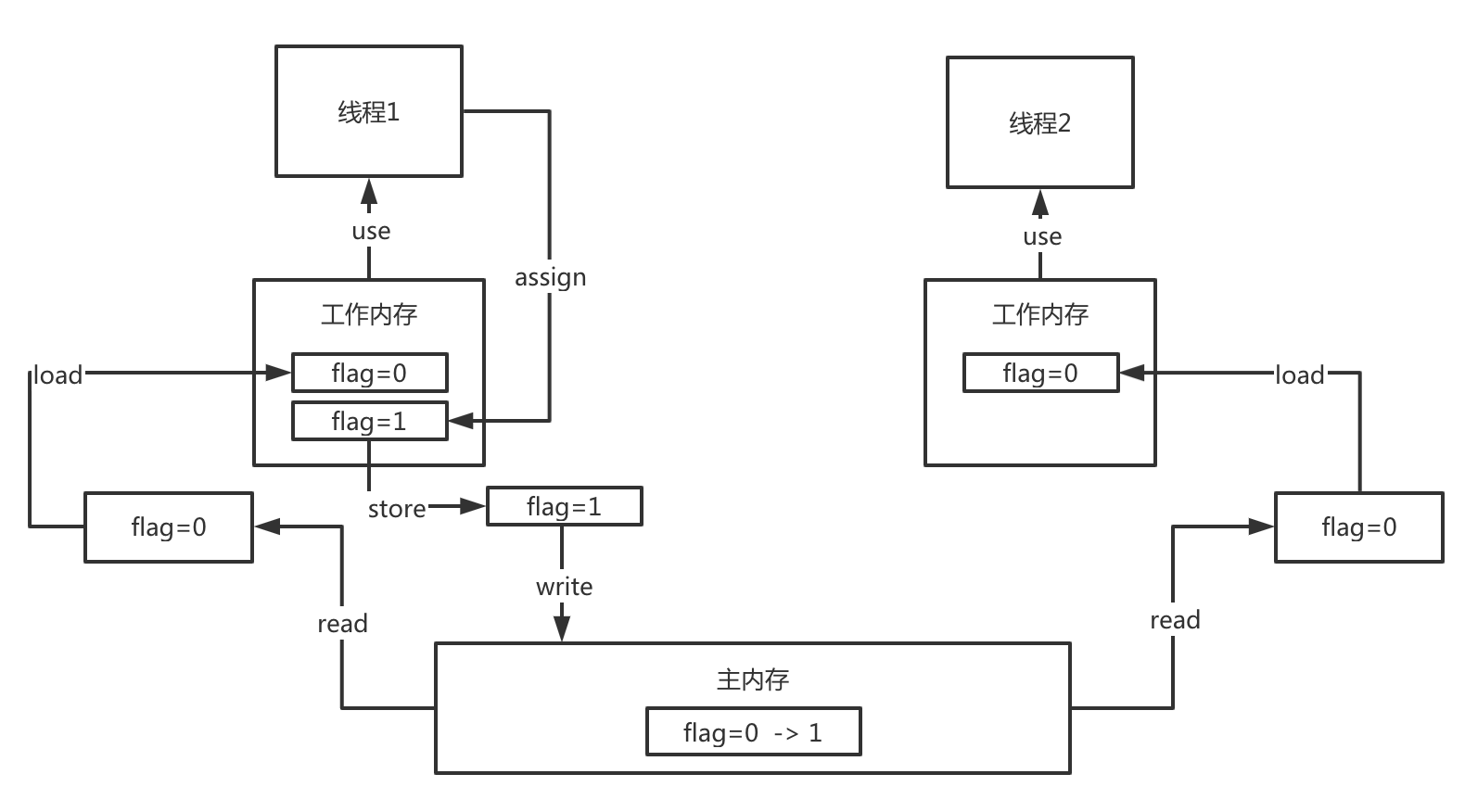
以这个图为例,线程1从主内存读取flag变量,并进行了修改,写入到了工作内存,有可能它只是在工作内存中,没有存入主内存,也就是还没有执行store和write指令,那么线程2来读取flag变量,读到的就依然还是0。
volatile保证可见性
如果变量加了volatile修饰,他就能保证线程1在执行了assign指令后,马上就跟着执行store+write指令,将数据写入到主内存中,然后还将其他线程的工作内存中值,标记为过期。线程2在发现变量过期以后,会重新从主内存中读取新的值,从而保证可见性。
volatile无法保证原子性
在Java里,像i++这种操作,他在底层执行的时候是多个指令,分别是读取和写入,既然涉及2个操作,就完全有可能在2个线程都读取后,一个线程才完成写入操作,他们读取和写入值,就是一样的。
volatile底层原理
lock指令
前面说了volatile是如何保证可见性的,但是在计算机底层,到底发送了什么指令来实现的效果呢?
对volatile修饰的变量,执行写操作的话,JVM会发送一条lock前缀指令给CPU,CPU在计算完之后会立即将这个值写回主内存,同时因为有MESI缓存一致性协议,所以各个CPU都会对总线进行嗅探,自己本地缓存中的数据是否被别人修改。
如果发现别人修改了某个缓存的数据,那么CPU就会将自己本地缓存的数据过期掉,然后这个CPU上执行的线程在读取那个变量的时候,就会从主内存重新加载最新的数据了。
lock前缀指令 + MESI缓存一致性协议保证了可见性。
内存屏障:禁止重排序
volatile可以保证有序性,那么它是如何做到的呢?
它是通过内存屏障来实现的,有这么几种内存屏障,分别对应几种场景
1 | Load1: |
LoadLoad屏障:Load1;LoadLoad;Load2,确保Load1数据的装载先于Load2后所有装载指令,他的意思,Load1对应的代码和Load2对应的代码,是不能指令重排的
1 | Store1: |
StoreStore屏障:Store1;StoreStore;Store2,确保Store1的数据一定刷回主存,对其他cpu可见,先于Store2以及后续指令
以及
LoadStore屏障:Load1;LoadStore;Store2,确保Load1指令的数据装载,先于Store2以及后续指令
StoreLoad屏障:Store1;StoreLoad;Load2,确保Store1指令的数据一定刷回主存,对其他cpu可见,先于Load2以及后续指令的数据装载
怎么理解这几个屏障呢?
1 | volatile variable = 1 |
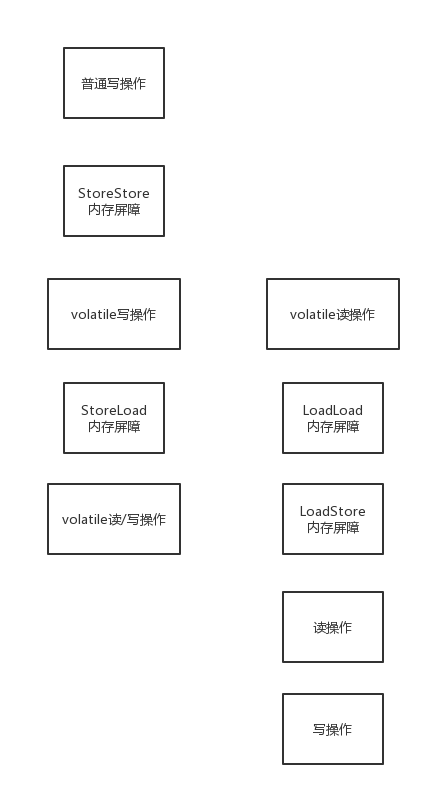
对于volatile修饰变量的读写操作,都会加入内存屏障。
每个volatile写操作前面,都会加入StoreStore屏障,禁止普通写和volatile写重排,每个volatile写操作后面,会加入StoreLoad屏障,禁止跟后面的volatile读/写重排。
每个volatile读操作后面,加LoadLoad屏障,禁止下面的普通读和voaltile读重排;每个volatile读操作后面,加LoadStore屏障,禁止后面的普通写和volatile读重排
再谈内存屏障
线程1:
Release屏障
isRunning = false;
Store屏障
线程2:
Load屏障
while(isRunning) {
Acquire屏障
// 代码逻辑
}
在volatile变量写操作的前面会加入一个Release屏障,然后在之后会加入一个Store屏障,这样就可以保证volatile写跟Release屏障之前的任何读写操作都不会指令重排,然后Store屏障保证了,写完数据之后,立马会执行flush处理器缓存的操作
在volatile变量读操作的前面会加入一个Load屏障,这样就可以保证对这个变量的读取时,如果被别的处理器修改过了,必须得从其他处理器的高速缓存(或者主内存)中加载到自己本地高速缓存里,保证读到的是最新数据;在之后会加入一个Acquire屏障,禁止volatile读操作之后的任何读写操作会跟volatile读指令重排序。
其实Acquire屏障就是LoadLoad屏障 + LoadStore屏障,Release屏障其实就是StoreLoad屏障 + StoreStore屏障。
不同版本的JVM,不同的底层硬件,都可能会导致加的内存屏障有一些区别,这个本来就没完全一致的。只要知道内存屏障是如何保证volatile的可见性和有序性的就可以了。
总结
本文系统讲解了相关技术要点。通过学习掌握核心概念和实践方法,提升技术能力。
关键要点
- 理解核心技术原理
- 掌握实际应用方法
- 学习最佳实践和注意事项
实践建议
- 结合实际项目练习
- 深入研究官方文档
- 持续学习和实践