高可用缓存架构实战 06:缓存雪崩及解决方案
此为龙果学院课程笔记,记录以供以后翻看
缓存雪崩
缓存雪崩这种场景,缓存架构中非常重要的一个环节,应对缓存雪崩的解决方案,避免缓存雪崩的时候,造成整个系统崩溃,带来巨大的经济损失
概述
本文系统讲解Redis缓存架构的核心技术,包括持久化配置、高可用方案和最佳实践。
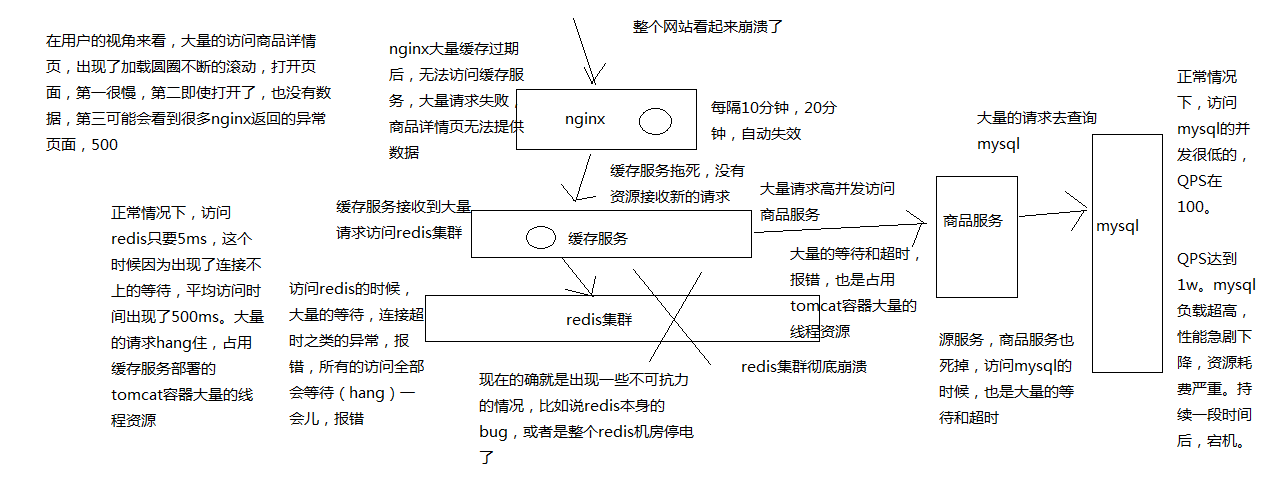
缓存雪崩的过程和后果
缓存雪崩,一般首先是redis集群彻底崩溃,它导致崩溃的流程如下:
- redis集群彻底崩溃
- 缓存服务大量对redis的请求hang住,占用资源
- 缓存服务大量的请求打到源头服务去查询mysql,直接打死mysql
- 源头服务因为mysql被打死也崩溃,对源服务的请求也hang住,占用资源
- 缓存服务大量的资源全部耗费在访问redis和源服务无果,最后自己被拖死,无法提供服务
- nginx无法访问缓存服务,redis和源服务,只能基于本地缓存提供服务,但是缓存过期后,没有数据提供
- 网站崩溃
缓存雪崩的解决方案
相对来说,考虑的比较完善的一套方案,分为事前,事中,事后三个层次去思考怎么来应对缓存雪崩的场景
事前解决方案
所谓事前解决方案,就是发生缓存雪崩之前,事情之前,怎么去避免redis彻底挂掉。
那就是保证redis的高可用性,我们利用redis本身的高可用性,复制,主从架构等功能,操作主节点去读写,数据同步到从节点,一旦主节点挂掉,从节点就跟上。
一般是建议双机房部署,一套redis cluster,部分机器在一个机房,另一部分机器在另外一个机房。
还有一种部署方式,两套redis cluster,两套redis cluster之间做一个数据的同步,redis集群是可以搭建成树状的结构的。一旦单个机房出了故障,至少另外一个机房还能有些redis实例提供服务。
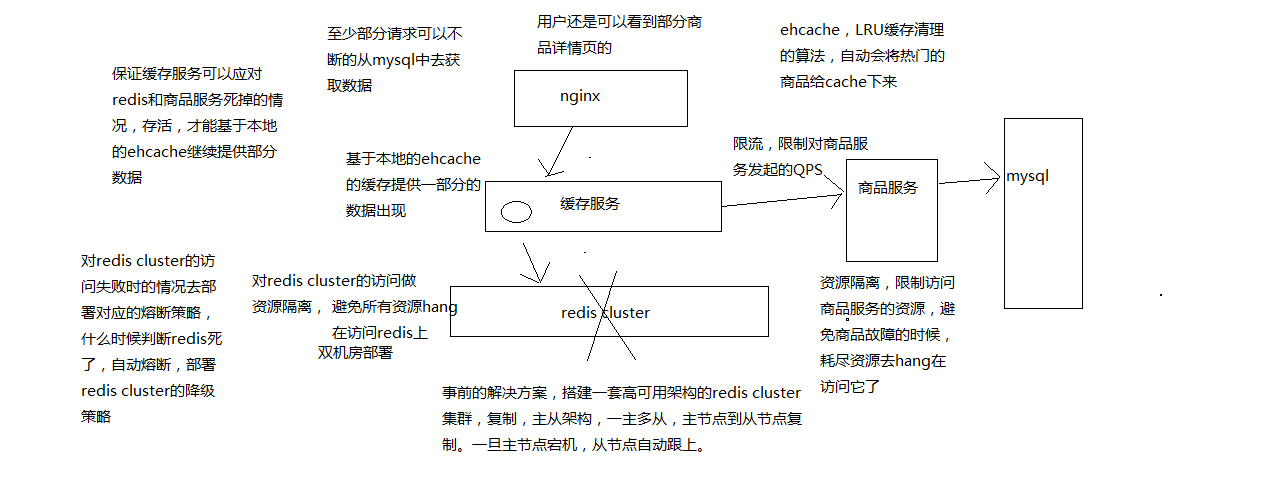
事中解决方案
如果redis cluster已经彻底崩溃了,已经开始大量的访问无法访问到redis了,那之前文章讲到过的多级缓存就起作用了。
ehcache缓存,第一应对零散的redis中数据被清除掉的现象,另外一个主要是预防redis彻底崩溃。这样多台机器上部署的缓存服务实例的内存中,还有一套ehcache的缓存,可以基于本地的ehcache的缓存提供一部分的数据。
一旦redis集群彻底崩溃了需要做以下几个步骤:
- 对redis的访问做资源隔离,避免所有资源hang在访问redis上
- 对redis访问失败的情况做相应的熔断和降级策略
- 使用ehcache本地缓存
- 对源服务访问的限流以及资源隔离(mysql层)
事后解决方案
如何恢复Redis Cluster,有两种情况
- redis数据可以恢复,做了备份,redis数据备份和恢复,redis重新启动起来
- redis数据彻底丢失了,或者数据过旧,快速缓存预热,redis重新启动起来
其实这套方案没什么东西,事前的Redis文章前面也说了,事中ehcache也做过了。但是,如何将缓存服务如何设计成高可用的架构,需要配合Hystrix来开发。我们的熔断,降级,限流等等操作都需要Hystrix的配合。
使用Hystrix对Redis进行资源隔离
接下来就要对redis的访问这一块加上保护措施,给商品服务的访问加上限流的保护措施。redis这一块,全都用hystrix的command进行封装,做资源隔离,确保redis的访问只能在固定的线程池内的资源来进行访问,哪怕是redis访问的很慢,有等待和超时,也不要紧,只有少量额线程资源用来访问,缓存服务不会被拖垮。
找到之前的缓存项目https://github.com/sail-y/eshop-cache ,引入Hystrix的依赖
1 | <dependency> |
在CacheServiceImpl里有几处用到redis的地方,我们就需要开发几个相应的command。
SaveProductInfo2RedisCacheCommand
SaveProductInfo2RedisCacheCommand.java
1 | /** |
然后用command替换之前的实现
CacheServiceImpl.saveProductInfo2RedisCache
1 | /** |
SaveShopInfo2RedisCacheCommand
SaveShopInfo2RedisCacheCommand.java
1 | /** |
然后用command替换之前的实现
CacheServiceImpl.saveShopInfo2RedisCache
1 | /** |
GetProductInfoFromRedisCacheCommand
GetProductInfoFromRedisCacheCommand.java
1 | /** |
然后用command替换之前的实现
CacheServiceImpl.getProductInfoFromRedisCache
1 | /** |
GetShopInfoFromRedisCacheCommand
GetShopInfoFromRedisCacheCommand.java
1 | /** |
然后用command替换之前的实现
CacheServiceImpl.getShopInfoFromRedisCache
1 | /** |
使用Hystrix对Redis访问进行降级
上面已经通过hystrix command对redis的访问进行了资源隔离,避免redis访问频繁失败,或者频繁超时的时候,耗尽大量的tomcat容器的资源去hang在redis的访问上。
这样就限定只有一部分线程资源可以用来访问redis,如果redis集群彻底崩溃了,这个时候,可能command对redis的访问大量的报错和timeout超时,熔断(短路),我们就需要对redis进行降级,用Hystrix的fallback机制。建议是使用fail silent模式,fallback里面直接返回一个空值,比如一个null,最简单。
在外面调用redis的代码(CacheService类),只要你把timeout、熔断、熔断恢复、降级,都做好了,是感知不到redis的访问异常的。可能会出现的情况是,当redis集群崩溃的时候,CacheService会获取到的是大量的null空值。
根据这个null空值,我们还可以去做多级缓存的降级访问,nginx本地缓存,redis分布式集群缓存,ehcache本地缓存等等。
1 |
|
顺便回顾一下之前CacheController的代码,在从redis里获取null值以后,会自动去别的地方一步步获取。
1 |
|
经过这样一个简单的改造,我们使用Hystrix对redis的线程资源隔离和降级都很容易的完成了。
Redis集群崩溃定制化熔断策略
缓存雪崩的事中解决方案
redis集群崩溃的时候,Hystrix会怎么样?
- 大量的等待,超时,报错
- 如果是短时间内报错,会直接走fallback降级,直接返回null
- 超时控制,应该是判断redis访问超过了多长时间,就直接给报错timeout了
不推荐用默认的值,一般不太精准,redis的访问先统计一下访问时长的百分比,hystrix dashboard里可以看到TP90,TP95,TP99的时间分别是多少。一般redis访问TP99在100ms以内,那么此时timeout时长稍微设置多一些,比如100ms。
timeout设置
HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(int value)
意义在于哪里?一旦redis出现了大面积的故障,此时肯定是访问的时候大量的超过100ms,大量的在等待和超时,这样就可以确保大量的请求不会hang住过长的时间,比如hang住个1s,500ms。如果100ms直接就报timeout,就会走fallback降级了。
熔断策略
开启熔断有2个参数
circuitBreaker.requestVolumeThreshold
设置一个rolling window,滑动窗口中,最少要有多少个请求时,才触发开启短路。举例,如果设置为20(默认值),那么在一个10秒的滑动窗口内,如果只有19个请求,即使这19个请求都是异常的,也是不会触发开启短路器的。
HystrixCommandProperties.Setter()
.withCircuitBreakerRequestVolumeThreshold(int value)
我们应该根据我们自己的平时的访问流量去设置,而不是用默认值,比如,我们认为平时一般的时候,流量也可以在每秒在QPS 100,10秒的滑动窗口就是1000,一般可以设置600或者800一个值,需要根据自己的系统的流量去设置。假如你设置的太少了,或者太多了,都不太合适。举个例子,你设置一个20,结果在晚上最低峰的时候,刚好是30,可能晚上的时候因为访问不频繁,大量的找不到缓存,可能超时频繁了一些,结果直接就给短路了。
circuitBreaker.errorThresholdPercentage
设置异常请求量的百分比,当异常请求达到这个百分比时,就触发打开短路器,默认是50,也就是50%
1 | HystrixCommandProperties.Setter() |
我们最好还是自己定制,自己设置,如果是要50%的时候才短路的话,会有什么情况呢?10%短路,也不太靠谱,90%异常,才短路也不行。这个值可以稍微高一些,如果redis集群彻底崩溃,那么基本上就是所有的请求,100%都会异常,所以一般设置60%,70%。也有可能偶然出现网络的抖动,导致比如就这10秒钟,访问延时高了一些,其实可能并不需要立即就短路,可能下个10秒马上就恢复了。
金融支付类的接口,可能这个比例就会设置的很低,因为对异常系统必须要很敏感,可能就是10%异常了,就直接短路了,不让继续访问了。金融支付类的接口是很重要的,而且必须是很稳定,我们不能容忍任何的延迟或者是报错。一旦支付类的接口,有10%的异常的话,我们基本就可以认为这个接口已经出问题了,再继续访问的话,也许访问的就是有问题的接口,可能造成资金的错乱,给公司造成损失。所以直接熔断吧,不让访问了,走降级策略,这就是对整个系统的一个安全性保障。
circuitBreaker.sleepWindowInMilliseconds
设置在短路之后,需要在多长时间内直接reject请求,然后在这段时间之后,再重新导half-open状态,尝试允许请求通过以及自动恢复,默认值是5000毫秒
1 | HystrixCommandProperties.Setter() |
如果redis集群崩溃了,会在5s内就直接恢复。
Hystrix保护源服务,防止Mysql崩溃
做缓存服务,redis集群彻底崩溃的时候,除了对redis本身做资源隔离、超时控制、熔断策略。还要保护源服务,因为Redis集群崩溃后,大量的请求会高并发会去访问源服务-商品服务(提供商品数据)。如果QPS10000去访问商品服务,基于mysql去查询,那mysql肯定会挂掉,商品服务也就死掉了。
所以要对商品服务这种源服务的访问施加限流的措施,限流怎么限,hystrix本身就是提供了两种机制,线程池(内部做了异步化处理,可以处理超时),semaphore(信号量,让tomcat线程执行运行逻辑,没有内部的异步化处理,一旦超时,会导致tomcat线程就hang住了)。
一般推荐线程池用来做有网络访问的这种资源隔离,因为涉及到网络,就很容易超时;sempahore是用来做对服务纯内存的一些复杂业务逻辑的操作进行限流,因为不涉及网络访问,就是纯粹为了避免对内存内的复杂业务逻辑进行太高并发的访问,造成系统本身的故障。semaphore在以下情况是很合适的:比如一些推荐、搜索,有部分算法,复杂的算法,是放在服务内部纯内存去运行的,一个服务暴露出来的就是某个算法的执行。
我们这里是访问外部的商品服务,所以还是用线程池做限流,需要算一下,要限多少,怎么限?
假设每次商品服务的访问性能在200ms,1个线程一秒可以执行5次访问,假设我们一个缓存服务实例对这个商品服务的访问每秒在150次。所以这个时候,我们就需要30个线程,每个线程每秒可以访问5次,总共每秒30个线程可以访问150次。
我们算的这个每秒150次访问时正常情况下,如果是非正常情况下,每秒1000次,甚至1w次,此时就可以自然限流,因为我们的线程池就30个。在非正常情况下,直接线程池+等待队列全满,此时就会出现大量的reject操作,然后就会去调用降级逻辑。接着我们要做限流,设置的就是线程池的大小,还有等待队列的大小,30个线程可以每秒处理150个请求,但是偶尔会多一些出来,同时30个线程处理150个请求会快一些,不用花费1秒钟,等待队列给一些buffer,不要偶尔1秒钟来了200条请求,50条直接给reject掉了。等待队列设置150个,30个线程直接500ms处理完了,等待队列中的50个请求就可以继续处理。
1 | public class GetProductInfoCommand extends HystrixCommand<ProductInfo> { |
源服务fallback降级机制
现在nginx本地缓存没有,redis集群崩溃,ehcache也找不到这条数据对应的缓存,只能去源头服务里面查询,但是查询的请求又被限流了,现在请求到了这里,被限流了以后只能走降级逻辑。
这里的一种降级机制叫做stubbed fallback降级机制(残缺的降级),就是用请求参数中少量的数据,加上纯内存中缓存的少量的数据来提供残缺的数据服务。
缓存雪崩预防和解决方案回顾
事前,redis高可用性,redis cluster,sentinal,复制,主从,从->主,双机房部署
事中,ehcache可以扛一扛,redis挂掉之后的资源隔离、超时控制、熔断,商品服务的访问限流、多级降级,缓存服务在雪崩场景下存活下来,基于ehcache和存活的商品服务提供数据
事后,快速恢复Redis,备份+恢复,快速的缓存预热的方案
缓存穿透
如果一直访问的根本不存在的时候,那么就会导致缓存穿透,所有的这种请求都会直接到mysql这边来。
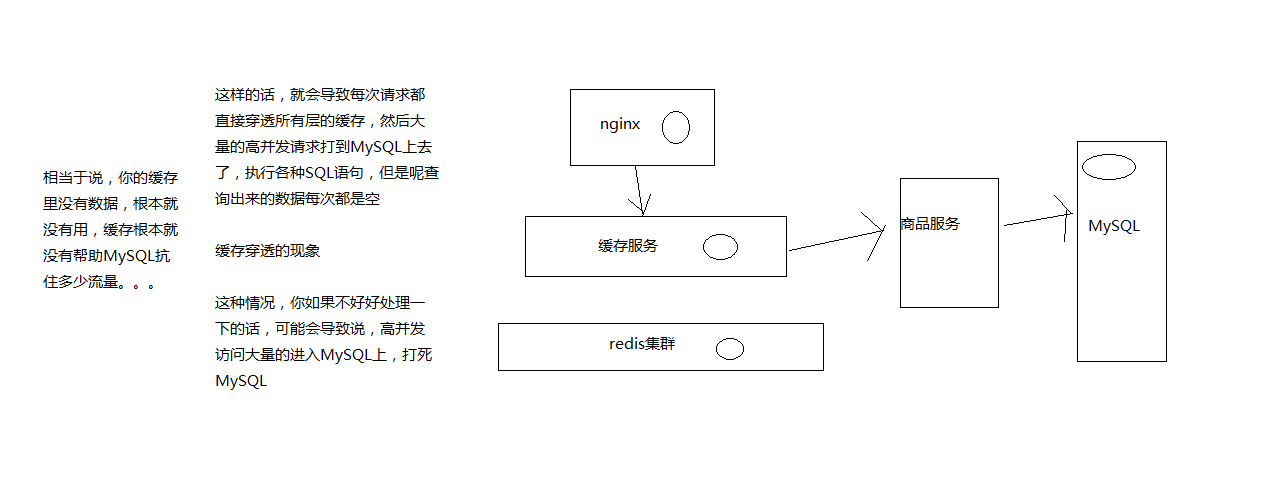
缓存穿透的解决方案其实非常简单,就是如果从源服务(商品服务)查询到的数据是空,就说明这个数据根本就不存在。那么如果这个数据不存在的话,我们也往redis和ehcache等缓存中写入一个数据,可以写入一个空的数据,比如空的productInfo的json串,给nginx也是,返回一个空的productInfo的json串。
我们有异步监听数据变更的机制在里面,如果数据变更的话,某个数据本来是没有的,可能会导致缓存穿透,所以我们给了个空数据,但是现在这个数据有了,我们接收到这个变更的消息过后,就可以将数据再次从源服务中查询出来,然后设置到各级缓存中去了。
缓存失效
之前在nginx中设置本地的缓存的时候,给了一个过期的时间(10分钟)。10分钟以后自动过期,过期了以后,就会重新从redis中去获取数据。10分钟到期自动过期,就叫做缓存的失效。如果缓存失效以后,那么实际上此时,就会有大量的请求回到redis中去查询。
如果同一时间来了1000个请求,都将缓存cache在了nginx自己的本地,缓存失效的时间都设置了10分钟,那么是不是可能导致10分钟过后,这些数据,就自动全部在同一时间失效了。如果同一时间全部失效,会不会导致同一时间大量的请求过来,在nginx里找不到缓存数据,全部高并发走到redis上去了。加重大量的网络请求,网络负载也会加重。
解决方案很简单,就是把10分钟的时间改成一个随机数,随机一个失效的时间。
1 | math.randomseed(tostring(os.time()):reverse():sub(1, 7)) |
总结
本文系统讲解了Redis缓存架构的关键技术要点。通过合理的缓存设计和持久化配置,可以有效提升系统性能和数据安全性。建议根据实际业务场景选择合适的缓存策略,并做好监控和运维工作。
关键要点
- 理解缓存架构的核心设计原则
- 掌握Redis持久化机制的配置方法
- 学习企业级缓存方案的最佳实践
实践建议
- 根据业务特点选择合适的持久化策略
- 建立完善的监控和告警机制
- 定期备份和演练故障恢复流程