此为龙果学院课程学习笔记,记录以后翻看
快速入门 环境准备和安装
安装JDK,至少1.8.0_73以上版本,java -version
下载和解压缩Elasticsearch安装包(https://www.elastic.co/downloads/past-releases/elasticsearch-5-2-0)
启动Elasticsearch:bin\elasticsearch,es本身特点之一就是开箱即用,如果是中小型应用,数据量少,操作不是很复杂的,直接启动就可以用了。
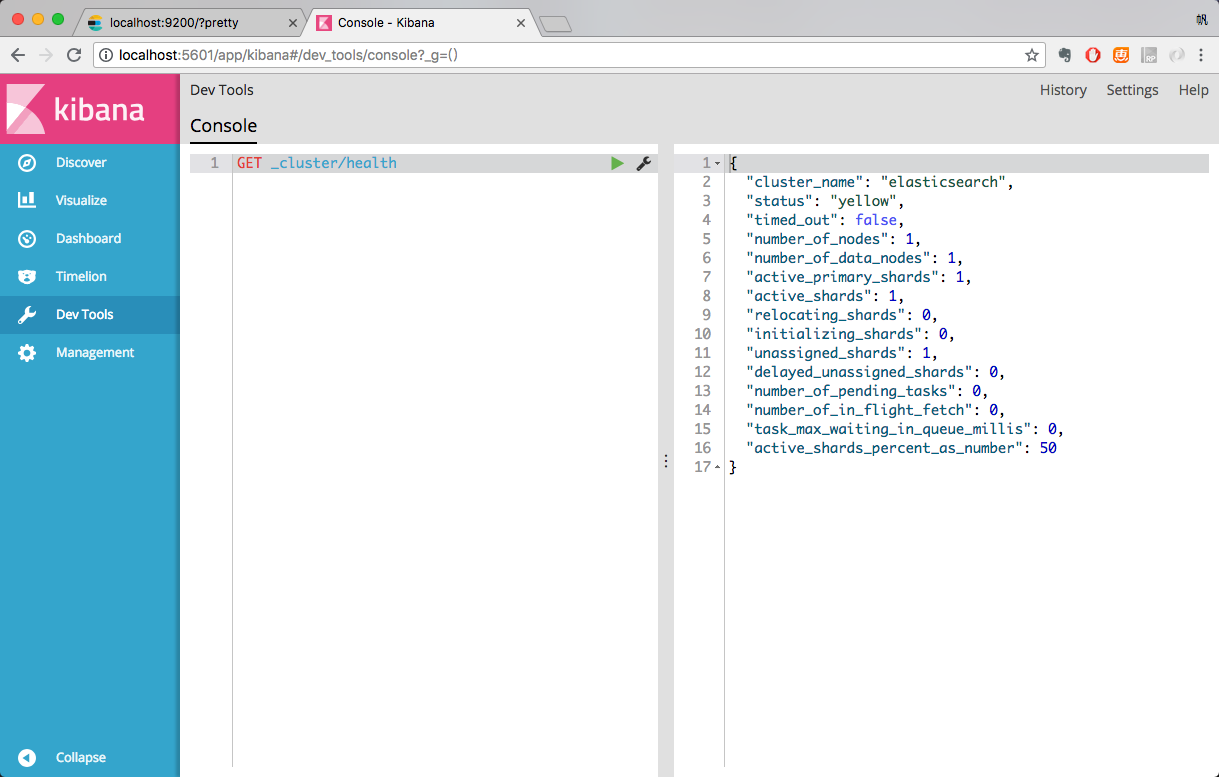
检查ES是否启动成功:http://localhost:9200/?pretty
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 name: node名称 cluster_name: 集群名称(默认的集群名称就是elasticsearch) version.number: 5.2.0,es版本号 { "name" : "4onsTYV" , "cluster_name" : "elasticsearch" , "cluster_uuid" : "nKZ9VK_vQdSQ1J0Dx9gx1Q" , "version" : { "number" : "5.2.0" , "build_hash" : "24e05b9" , "build_date" : "2017-01-24T19:52:35.800Z" , "build_snapshot" : false , "lucene_version" : "6.4.0" }, "tagline" : "You Know, for Search" }
修改集群名称:elasticsearch.yml
修改elasticsearch.yml里面的cluster.name: my-application即可。
下载和解压缩Kibana安装包,使用里面的开发界面,去操作elasticsearch,作为我们学习es知识点的一个主要的界面入口
https://www.elastic.co/downloads/past-releases/kibana-5-2-0
访问http://localhost:5601/,使用devtools进行测试和开发
hello world 学习一门新技术,搭建好环境后第一件事当然是做个helloworld的demo,我们来做个crud
document数据格式
es的数据结构存储模式,熟悉mongodb的人应该知道,他们的数据结构是差不多的,都是面向文档的,一条数据就是一个json。
对象数据存储到数据库中,只能拆解开来,变为扁平的多张表,每次查询的时候还得还原回对象格式,相当麻烦。
ES是面向文档的,文档中存储的数据结构,与面向对象的数据结构是一样的,基于这种文档数据结构,es可以提供复杂的索引,全文检索,分析聚合等功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Employee private String email; private String firstName; private String lastName; private EmployeeInfo info; private Date joinDate; } private class EmployeeInfo private String bio; private Integer age; private String[] interests; } EmployeeInfo info = new EmployeeInfo(); info.setBio("curious and modest" ); info.setAge(30 ); info.setInterests(new String[]{"bike" , "climb" }); Employee employee = new Employee(); employee.setEmail("zhangsan@sina.com" ); employee.setFirstName("san" ); employee.setLastName("zhang" ); employee.setInfo(info); employee.setJoinDate(new Date());
上述代码,在mysql中,肯定就是两张表:employee表,employee_info表,将employee对象的数据重新拆开来,变成Employee数据和EmployeeInfo数据
demo背景 有一个电商网站,需要为其基于ES构建一个后台系统,提供以下功能:
对商品信息进行CRUD(增删改查)操作
执行简单的结构化查询
可以执行简单的全文检索,以及复杂的phrase(短语)检索
对于全文检索的结果,可以进行高亮显示
对数据进行简单的聚合分析
简单的集群管理 快速检查集群的健康状况 es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
1 2 epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 1528602515 11:48:35 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
如何快速了解集群的健康状况?green、yellow、red?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
为什么现在会处于一个yellow状态?
我们现在就一个笔记本电脑,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
做一个小实验:此时只要启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去,然后cluster status就会变成green状态。
快速查看集群中有哪些索引 GET /_cat/indices?v
1 2 health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open .kibana T5J6wa4FSy6ErH1zTOmIEg 1 1 1 0 3.1kb 3.1kb
简单的索引操作 创建索引:PUT /test_index?pretty
1 2 3 4 5 6 7 8 9 10 health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open test_index cyS7pUwcQKmvTFtUCGNgHg 5 1 0 0 650b 650b yellow open .kibana T5J6wa4FSy6ErH1zTOmIEg 1 1 1 0 3.1kb 3.1kb ``` 删除索引:DELETE /test_index?pretty ```text health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open .kibana T5J6wa4FSy6ErH1zTOmIEg 1 1 1 0 3.1kb 3.1kb
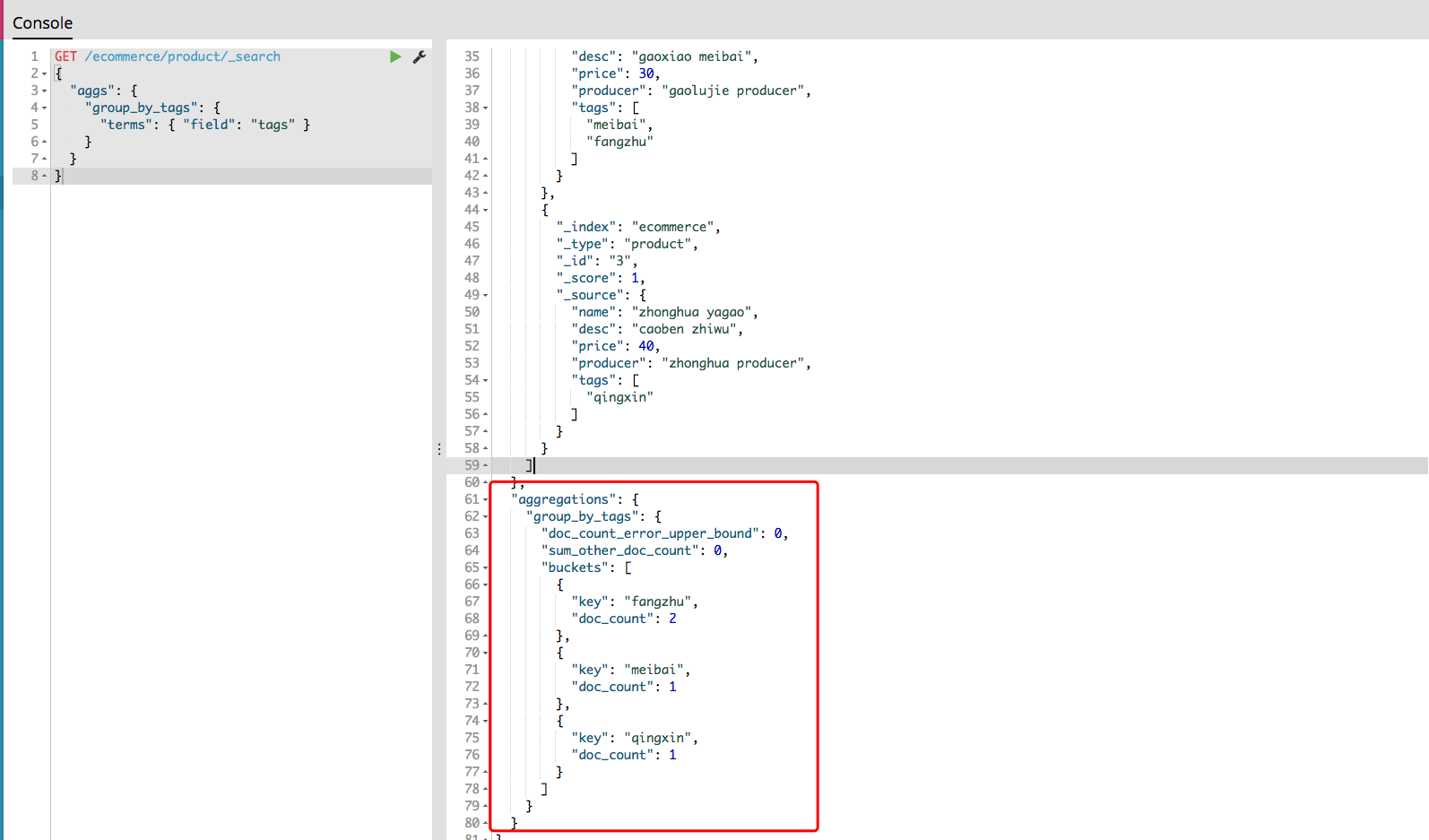
商品的CRUD操作 新增商品:新增文档,建立索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 PUT /ecommerce/product/1 { "name" : "gaolujie yagao" , "desc" : "gaoxiao meibai" , "price" : 30 , "producer" : "gaolujie producer" , "tags" : [ "meibai" , "fangzhu" ] } { "_index" : "ecommerce" , "_type" : "product" , "_id" : "1" , "_version" : 1 , "result" : "created" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 }, "created" : true } PUT /ecommerce/product/2 { "name" : "jiajieshi yagao" , "desc" : "youxiao fangzhu" , "price" : 25 , "producer" : "jiajieshi producer" , "tags" : [ "fangzhu" ] } PUT /ecommerce/product/3 { "name" : "zhonghua yagao" , "desc" : "caoben zhiwu" , "price" : 40 , "producer" : "zhonghua producer" , "tags" : [ "qingxin" ] }
查询商品:检索文档 GET /index/type/id
GET /ecommerce/product/1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 { "_index" : "ecommerce" , "_type" : "product" , "_id" : "1" , "_version" : 1 , "found" : true , "_source" : { "name" : "gaolujie yagao" , "desc" : "gaoxiao meibai" , "price" : 30 , "producer" : "gaolujie producer" , "tags" : [ "meibai" , "fangzhu" ] } } ```
#### 修改商品:替换文档 ```json PUT /ecommerce/product/1 { "name" : "jiaqiangban gaolujie yagao" , "desc" : "gaoxiao meibai" , "price" : 30 , "producer" : "gaolujie producer" , "tags" : [ "meibai" , "fangzhu" ] } { "_index" : "ecommerce" , "_type" : "product" , "_id" : "1" , "_version" : 2 , "result" : "updated" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 }, "created" : false }
替换方式有一个不好,即使必须带上所有的field,才能去进行信息的修改,否则文档的数据结构会被修改。
修改商品:更新文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 POST /ecommerce/product/1/_update { "doc" : { "name" : "jiaqiangban gaolujie yagao" } } { "_index" : "ecommerce" , "_type" : "product" , "_id" : "1" , "_version" : 2 , "result" : "updated" , "_shards" : { "total" : 0 , "successful" : 0 , "failed" : 0 } }
删除商品:删除文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 DELETE /ecommerce/product/1 { "found" : true , "_index" : "ecommerce" , "_type" : "product" , "_id" : "1" , "_version" : 4 , "result" : "deleted" , "_shards" : { "total" : 2 , "successful" : 1 , "failed" : 0 } }
多种搜索方式 上面做了CRUD,接下里就是ES里最重要的搜索部分。
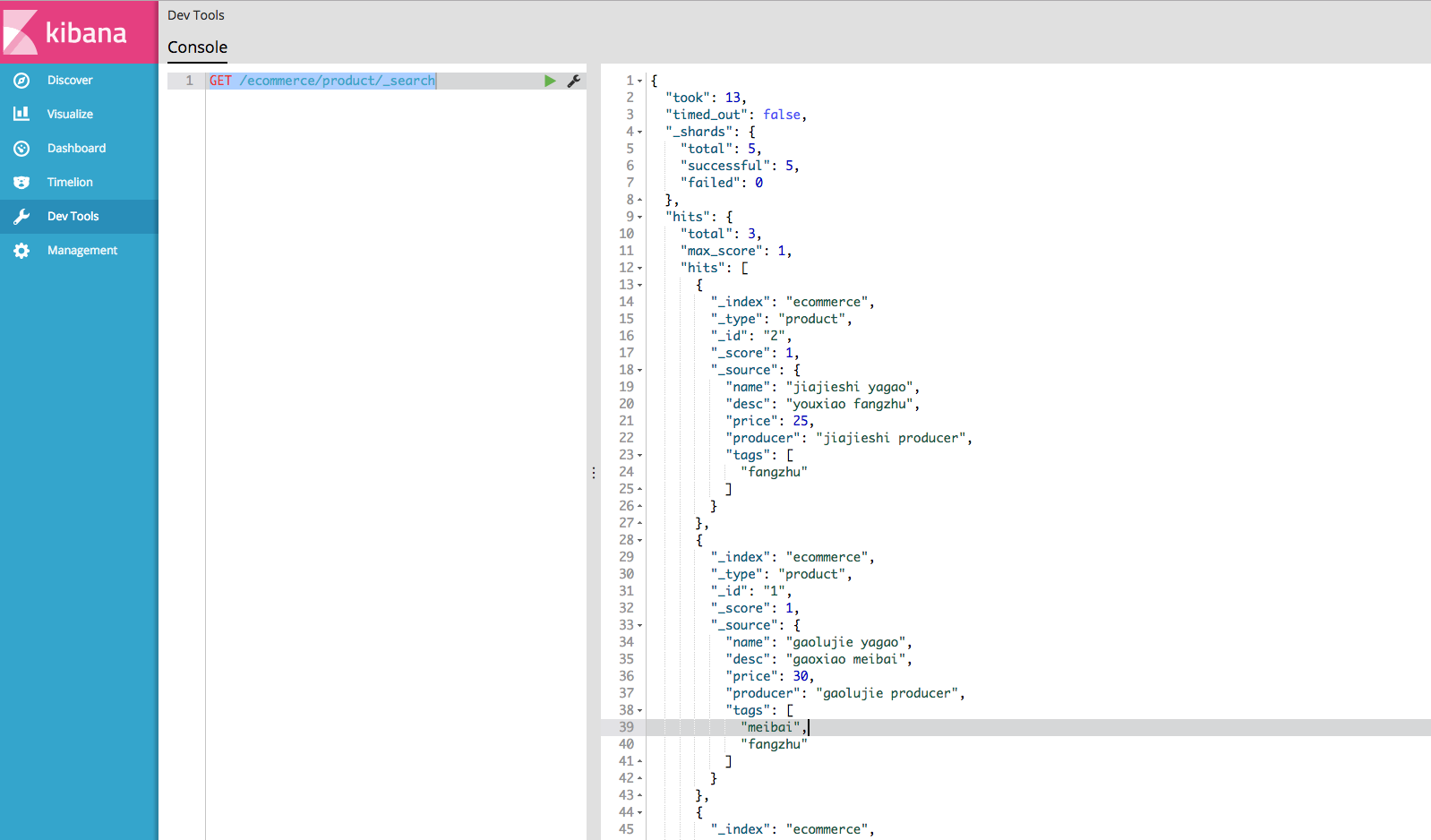
query string search 搜索全部商品:GET /ecommerce/product/_search
1 2 3 4 5 6 took:耗费了几毫秒 timed_out:是否超时,这里没有 _shards:数据拆成了5个分片,所以对于搜索请求,会分配所有的primary shard(或者是它的某个replica shard) hits.total:查询结果的数量,3个document hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高 hits.hits:包含了匹配搜索的document的详细数据
query string search的由来,因为search参数都是以http请求的query string来附带的(也就是?后面的)
搜索商品名称中包含yagao的商品,而且按照售价降序排序:
GET /ecommerce/product/_search?q=name:yagao&sort=price:desc
适用于临时的在命令行使用一些工具,比如curl,快速的发出请求,来检索想要的信息;但是如果查询请求很复杂,是很难去构建的。在生产环境中,几乎很少使用query string search
query DSL DSL:Domain Specified Language,特定领域的语言。
查询所有的商品
1 2 3 4 GET /ecommerce/product/_search { "query" : { "match_all" : {} } }
查询名称包含yagao的商品,同时按照价格降序排序
1 2 3 4 5 6 7 8 9 10 11 GET /ecommerce/product/_search { "query" : { "match" : { "name" : "yagao" } }, "sort" : [ { "price" : "desc" } ] }
分页查询商品,总共3条商品,假设每页就显示1条商品,现在显示第2页,所以就查出来第2个商品
1 2 3 4 5 6 GET /ecommerce/product/_search { "query" : { "match_all" : {} }, "from" : 1 , "size" : 1 }
指定要查询出来商品的名称和价格就可以
1 2 3 4 5 GET /ecommerce/product/_search { "query" : { "match_all" : {} }, "_source" : ["name" , "price" ] }
更加适合生产环境的使用,可以构建复杂的查询。
query filter 搜索商品名称包含yagao,而且售价大于25元的商品
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 GET /ecommerce/product/_search { "query" : { "bool" : { "must" : { "match" : { "name" : "yagao" } }, "filter" : { "range" : { "price" : { "gt" : 25 } } } } } }
full-text search(全文检索) 1 2 3 4 5 6 7 8 GET /ecommerce/product/_search { "query" : { "match" : { "producer" : "yagao producer" } } }
因为查询了2个单词,producer这个字段,会先被拆解,建立倒排索引。
在分词以后,只要任意命中其中一个单词,都会被查询出来,如果2个单词都命中会排在前面。
phrase search(短语搜索) 跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回。
phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回。
1 2 3 4 5 6 7 8 GET /ecommerce/product/_search { "query" : { "match_phrase" : { "producer" : "yagao producer" } } }
highlight search(高亮搜索结果) 1 2 3 4 5 6 7 8 9 10 11 12 13 GET /ecommerce/product/_search { "query" : { "match" : { "producer" : "producer" } }, "highlight" : { "fields" : { "producer" : {} } } }
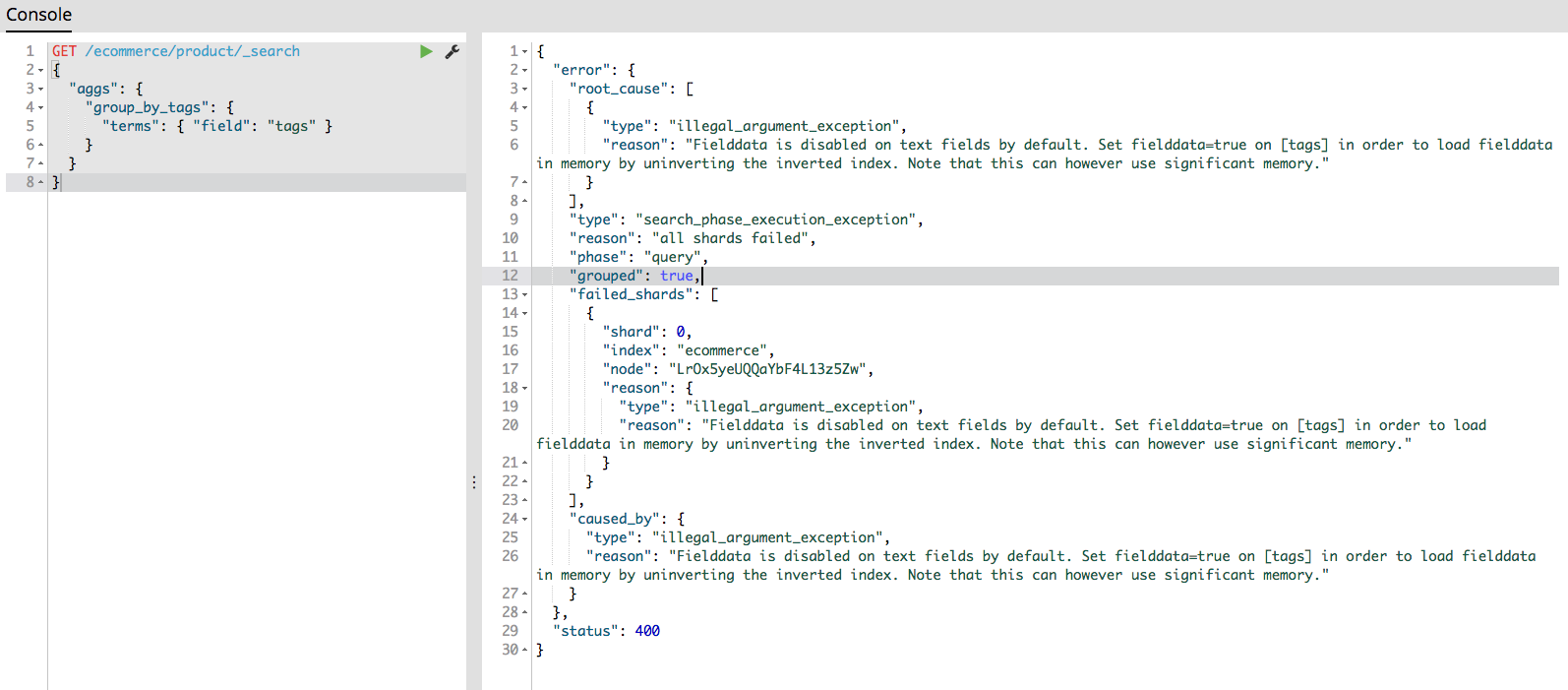
聚合分析快速入门 计算每个tag下的商品数量 1 2 3 4 5 6 7 8 GET /ecommerce/product/_search { "aggs" : { "group_by_tags" : { "terms" : { "field" : "tags" } } } }
报错了,text类型的字段默认不支持聚合,得做个操作让它支持聚合,将文本field的fielddata属性设置为true。
1 2 3 4 5 6 7 8 9 10 11 12 ``` ```json PUT /ecommerce/_mapping/product { "properties" : { "tags" : { "type" : "text" , "fielddata" : true } } }
再测试一次聚合查询,就好了
对名称中包含yagao的商品,计算每个tag下的商品数量 在聚合分析的基础上加上条件筛选
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 GET /ecommerce/product/_search { "size" : 0 , "query" : { "match" : { "name" : "yagao" } }, "aggs" : { "all_tags" : { "terms" : { "field" : "tags" } } } }
先分组,再算每组的平均值,计算每个tag下的商品的平均价格 1 2 3 4 5 6 7 8 9 10 11 12 13 14 GET /ecommerce/product/_search { "size" : 0 , "aggs" : { "group_by_tags" : { "terms" : { "field" : "tags" }, "aggs" : { "avg_price" : { "avg" : { "field" : "price" } } } } } }
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 { "took" : 22 , "timed_out" : false , "_shards" : { "total" : 5 , "successful" : 5 , "failed" : 0 }, "hits" : { "total" : 3 , "max_score" : 0 , "hits" : [] }, "aggregations" : { "group_by_tags" : { "doc_count_error_upper_bound" : 0 , "sum_other_doc_count" : 0 , "buckets" : [ { "key" : "fangzhu" , "doc_count" : 2 , "avg_price" : { "value" : 27.5 } }, { "key" : "meibai" , "doc_count" : 1 , "avg_price" : { "value" : 30 } }, { "key" : "qingxin" , "doc_count" : 1 , "avg_price" : { "value" : 40 } } ] } } }
计算每个tag下的商品的平均价格,并且按照平均价格降序排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 GET /ecommerce/product/_search { "size" : 0 , "aggs" : { "all_tags" : { "terms" : { "field" : "tags" , "order" : { "avg_price" : "desc" } }, "aggs" : { "avg_price" : { "avg" : { "field" : "price" } } } } } }
按照指定的价格范围区间进行分组,然后在每组内再按照tag进行分组,最后再计算每组的平均价格 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 GET /ecommerce/product/_search { "size" : 0 , "aggs" : { "group_by_price" : { "range" : { "field" : "price" , "ranges" : [ { "from" : 0 , "to" : 20 }, { "from" : 20 , "to" : 40 }, { "from" : 40 , "to" : 50 } ] }, "aggs" : { "group_by_tags" : { "terms" : { "field" : "tags" }, "aggs" : { "average_price" : { "avg" : { "field" : "price" } } } } } } } }