Hystrix实战 02:流程与原理详解
此为龙果学院课程学习笔记,记录以后翻看
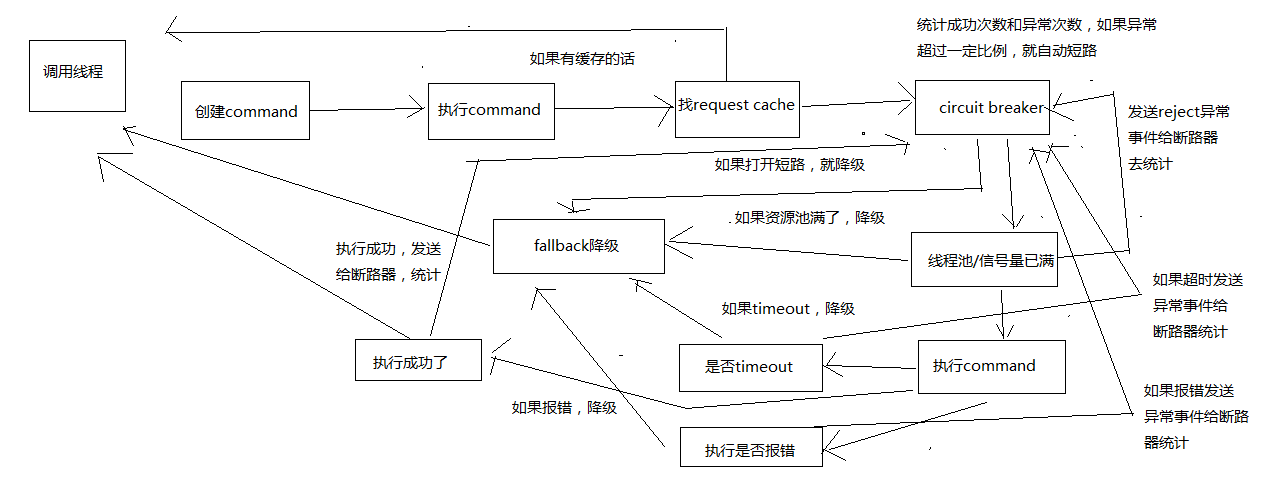
Hystrix流程讲解
创建Command
一个HystrixCommand或一个HystrixObservableCommand对象,代表了对某个依赖服务发起的一次请求或者调用,构造的时候,可以在构造函数中传入任何需要的参数。
HystrixCommand主要用于仅仅会返回一个结果的调用
HystrixObservableCommand主要用于可能会返回多条结果的调用
1 | HystrixCommand command = new HystrixCommand(arg1, arg2); |
执行Command
执行Command就可以发起一次对依赖服务的调用
要执行Command,需要在4个方法中选择其中的一个:execute(),queue(),observe(),toObservable()
其中execute()和queue()仅仅对HystrixCommand适用
execute():调用后直接block住,属于同步调用,直到依赖服务返回单条结果,或者抛出异常
queue():返回一个Future,属于异步调用,后面可以通过Future获取单条结果
observe():订阅一个Observable对象,Observable代表的是依赖服务返回的结果,获取到一个那个代表结果的Observable对象的拷贝对象
toObservable():返回一个Observable对象,如果我们订阅这个对象,就会执行command并且获取返回结果
1 | K value = command.execute(); |
execute()实际上会调用queue().get().queue(),接着会调用toObservable().toBlocking().toFuture()
也就是说,无论是哪种执行command的方式,最终都是依赖toObservable()去执行的。
检查是否开启请求缓存
如果这个command开启了请求缓存,而且这个调用的结果在缓存中存在,那么直接从缓存中返回结果。
检查是否开启了断路器
检查这个command对应的依赖服务是否开启了断路器
如果断路器被打开了,那么hystrix就不会执行这个command,而是直接去执行fallback降级机制。
检查线程池/队列/semaphore是否已经满了
如果command对应的线程池/队列/semaphore已经满了,那么也不会执行command,而是直接去调用fallback降级机制。
执行command
调用HystrixObservableCommand.construct()或HystrixCommand.run()来实际执行这个command
HystrixCommand.run()是返回一个单条结果,或者抛出一个异常
HystrixObservableCommand.construct()是返回一个Observable对象,可以获取多条结果
如果HystrixCommand.run()或HystrixObservableCommand.construct()的执行,超过了timeout时长的话,那么command所在的线程就会抛出一个TimeoutException。
如果timeout了,也会去执行fallback降级机制,而且就不会管run()或construct()返回的值了。
断路健康检查
Hystrix会将每一个依赖服务的调用成功,失败,拒绝,超时,等事件,都会发送给circuit breaker断路器。断路器就会对调用成功/失败/拒绝/超时等事件的次数进行统计。断路器会根据这些统计次数来决定,是否要进行断路,如果打开了断路器,那么在一段时间内就会直接断路,然后如果在之后第一次检查发现调用成功了,就关闭断路器。
调用fallback降级机制
在以下几种情况中,hystrix会调用fallback降级机制:run()或construct()抛出一个异常,断路器打开,线程池/队列/semaphore满了,command执行超时了。
一般在降级机制中,都建议给出一些默认的返回值,比如静态的一些代码逻辑,或者从内存中的缓存中提取一些数据,尽量在这里不要再进行网络请求了
即使在降级中,一定要进行网络调用,也应该将那个调用放在一个HystrixCommand中,进行隔离
在HystrixCommand中,上线getFallback()方法,可以提供降级机制
在HystirxObservableCommand中,实现一个resumeWithFallback()方法,返回一个Observable对象,可以提供降级结果
如果fallback返回了结果,那么hystrix就会返回这个结果
对于HystrixCommand,会返回一个Observable对象,其中会发返回对应的结果
对于HystrixObservableCommand,会返回一个原始的Observable对象
如果没有实现fallback,或者是fallback抛出了异常,Hystrix会返回一个Observable,但是不会返回任何数据
不同的command执行方式,其fallback为空或者异常时的返回结果不同
对于execute(),直接抛出异常
对于queue(),返回一个Future,调用get()时抛出异常
对于observe(),返回一个Observable对象,但是调用subscribe()方法订阅它时,立即抛出调用者的onError方法
对于toObservable(),返回一个Observable对象,但是调用subscribe()方法订阅它时,立即抛出调用者的onError方法。
不同执行方式走的流程
execute(),获取一个Future.get(),然后拿到单个结果
queue(),返回一个Future
observer(),立即订阅Observable,然后启动8大执行步骤,返回一个拷贝的Observable,订阅时立即回调给你结果
toObservable(),返回一个原始的Observable,必须手动订阅才会去执行8大步骤
Request Cache
首先有一个概念,叫做reqeust context–请求上下文,一般来说在一个web应用中,会使用hystrix在一个filter里面,对每一个请求都施加一个请求上下文,在tomcat容器内,每一次请求就是一次请求上下文。
然后在这次请求上下文中,我们会去执行N多代码,调用N多依赖服务,有的依赖服务可能还会调用好几次,在一次请求上下文中,如果有多个command,参数都是一样的,调用的接口也是一样的,其实结果可以认为也是一样的。
那么这个时候,我们就可以让第一次command执行返回的结果被缓存在内存中,然后这个请求上下文中后续的其他对这个依赖的调用全部从内存中取用缓存结果就可以了。不用在一次请求上下文中反复多次的执行一样的command,提升整个请求的性能。
HystrixCommand和HystrixObservableCommand都可以指定一个缓存key,然后hystrix会自动进行缓存,接着在同一个request context内,再次访问的时候,就会直接取用缓存。用请求缓存,可以避免重复执行网络请求,多次调用一个command,那么只会执行一次,后面都是直接取缓存。
指定缓存key,只需要实现一个getCacheKey 方法:
1 |
|
实例
对于请求缓存(request caching),请求合并(request collapsing),请求日志(request log),等等技术,都必须自己管理HystrixReuqestContext的生命周期。
在一个请求执行之前,都必须先初始化一个request context
1 | HystrixRequestContext context = HystrixRequestContext.initializeContext(); |
然后在请求结束之后,需要关闭request context
1 | context.shutdown(); |
一般在Java Web应用中,都是通过filter过滤器来实现的。
1 | public class HystrixRequestContextFilter implements Filter { |
注册Filter
1 |
|
手动清理缓存
有时候可能需要手动清理缓存,Hystrix提供了方法。
1 | public static void flushCache(Long productId) { |
FallBack降级
hystrix在3种情况下会调用降级方法。
- 运行的程序报错了,error。
- 线程池/信号量满了,reject。
- 超时了,timeout。
如果路器发现异常事件的占比达到了一定的比例,直接开启断路,circuit breaker。降级方法可以返回一个自定义的结果,或者一个过期的数据。
降级是通过实现HystrixCommand.getFallBack()方法来实现的。
1 |
|
断路器工作原理
- 如果经过短路器的流量超过了一定的阈值,HystrixCommandProperties.circuitBreakerRequestVolumeThreshold()
- 如果断路器统计到的异常调用的占比超过了一定的阈值,HystrixCommandProperties.circuitBreakerErrorThresholdPercentage()
- 然后断路器从close状态转换到open状态
- 断路器打开的时候,所有经过该断路器的请求全部被短路,不调用后端服务,直接走fallback降级
- 经过了一段时间之后,HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds(),会half-open,让一条请求经过短路器,看能不能正常调用。如果调用成功了,那么就自动恢复,转到close状态。
断路器配置
circuitBreaker.enabled
控制断路器是否允许工作,包括跟踪依赖服务调用的健康状况,以及对异常情况过多时是否允许触发短路,默认是true。
1
2HystrixCommandProperties.Setter()
.withCircuitBreakerEnabled(boolean value)circuitBreaker.requestVolumeThreshold
设置一个rolling window,滑动窗口中,最少要有多少个请求时,才触发开启短路。举例来说,如果设置为20(默认值),那么在一个sleepWindowInMilliseconds秒的滑动窗口内,如果只有19个请求,即使这19个请求都是异常的,也是不会触发开启短路器的。
1
2HystrixCommandProperties.Setter()
.withCircuitBreakerRequestVolumeThreshold(int value)circuitBreaker.sleepWindowInMilliseconds
设置在断路之后,需要在多长时间内直接reject请求,然后在这段时间之后,再重新到holf-open状态,尝试允许请求通过以及自动恢复,默认值是5000毫秒。这个值也是设置滑动窗口长度的一个值。
1
2HystrixCommandProperties.Setter()
.withCircuitBreakerSleepWindowInMilliseconds(int value)circuitBreaker.errorThresholdPercentage
设置异常请求量的百分比,当异常请求达到这个百分比时,就触发打开短路器,默认是50,也就是50%。
1
2HystrixCommandProperties.Setter()
.withCircuitBreakerErrorThresholdPercentage(int value)circuitBreaker.forceOpen
如果设置为true的话,直接强迫打开短路器,相当于是手动短路了,手动降级,默认false。
1
2HystrixCommandProperties.Setter()
.withCircuitBreakerForceOpen(boolean value)circuitBreaker.forceClosed
如果设置为ture的话,直接强迫关闭短路器,相当于是手动停止短路了,手动升级,默认false。
1
2HystrixCommandProperties.Setter()
.withCircuitBreakerForceClosed(boolean value)
配置实战
配置一个断路器,流量要求是20,异常比例是50%,短路时间是5s。在command内加入一个判断,如果是productId=-1,那么就直接报错,触发异常执行。
写一个client测试程序,写入50个请求,前20个是正常的,但是后30个是productId=-1,然后继续请求,会发现。
1 | public class CircuitBreakerTest { |
断路器设计原则
- 每个服务都会调用几十个后端依赖服务,那些后端依赖服务通常是由很多不同的团队开发的
- 每个后端依赖服务都会提供它自己的client调用库,比如说用thrift的话,就会提供对应的thrift依赖
- client调用库随时会变更
- client调用库随时可能会增加新的网络请求的逻辑
- client调用库可能会包含诸如自动重试,数据解析,内存中缓存等逻辑
- client调用库一般都对调用者来说是个黑盒,包括实现细节,网络访问,默认配置,等等
- 在真实的生产环境中,经常会出现调用者,突然间惊讶的发现,client调用库发生了某些变化
- 即使client调用库没有改变,依赖服务本身可能有会发生逻辑上的变化
- 有些依赖的client调用库可能还会拉取其他的依赖库,而且可能那些依赖库配置的不正确
- 大多数网络请求都是同步调用的
- 调用失败和延迟,也有可能会发生在client调用库本身的代码中,不一定就是发生在网络请求中
线程池机制的优点如下:
- 任何一个依赖服务都可以被隔离在自己的线程池内,即使自己的线程池资源填满了,也不会影响任何其他的服务调用
- 服务可以随时引入一个新的依赖服务,因为即使这个新的依赖服务有问题,也不会影响其他任何服务的调用
- 当一个故障的依赖服务重新变好的时候,可以通过清理掉线程池,瞬间恢复该服务的调用,而如果是tomcat线程池被占满,再恢复就很麻烦
- 如果一个client调用库配置有问题,线程池的健康状况随时会报告,比如成功/失败/拒绝/超时的次数统计,然后可以近实时热修改依赖服务的调用配置,而不用停机
- 如果一个服务本身发生了修改,需要重新调整配置,此时线程池的健康状况也可以随时发现,比如成功/失败/拒绝/超时的次数统计,然后可以近实时热修改依赖服务的调用配置,而不用停机
- 基于线程池的异步本质,可以在同步的调用之上,构建一层异步调用层
线程池机制的缺点:
- 线程池机制最大的缺点就是增加了cpu的开销
- 每个command的执行都依托一个独立的线程,会进行排队,调度,还有上下文切换
- Hystrix官方自己做了一个多线程异步带来的额外开销,通过对比多线程异步调用+同步调用得出,Netflix API每天通过hystrix执行10亿次调用,每个服务实例有40个以上的线程池,每个线程池有10个左右的线程
- 最后,用hystrix的额外开销,就是给请求带来了3ms左右的延时,最多延时在10ms以内,相比于可用性和稳定性的提升,这是可以接受的
限流测试
限流的目的是为了保护过多的请求导致服务并发量过高而宕机。
withCoreSize:设置你的线程池的大小
withMaxQueueSize:设置的是你的等待队列,缓冲队列的大小
withQueueSizeRejectionThreshold:如果withMaxQueueSize<withQueueSizeRejectionThreshold,那么取的是withMaxQueueSize,反之,取得是withQueueSizeRejectionThreshold
1 | .andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter() |
基于线程池的限流测试代码:
1 |
|
超时问题
我们在调用一些第三方服务或者分布式系统的一些其他服务的时候,如果别的服务不稳定,导致大量超时,我们没有处理好,可能会导致我们自己的服务也会出问题,大量的线程卡死。所以我们必须做超时的控制,给我们的服务提供安全保护的措施。
execution.isolation.thread.timeoutInMilliseconds
手动设置timeout时长,一个command运行超出这个时间,就被认为是timeout,然后将hystrix command标识为timeout,同时执行fallback降级逻辑
默认是1000,也就是1000毫秒
HystrixCommandProperties.Setter().withExecutionTimeoutInMilliseconds(int value)execution.timeout.enabled
控制是否要打开timeout机制,默认是true
HystrixCommandProperties.Setter().withExecutionTimeoutEnabled(boolean value)
总结
hystrix的核心知识
- hystrix内部工作原理:8大执行步骤和流程
- 资源隔离:你如果有很多个依赖服务,高可用性,先做资源隔离,任何一个依赖服务的故障不会导致你的服务的资源耗尽,不会崩溃
- 请求缓存:对于一个request context内的多个相同command,使用request cache,提升性能
- 熔断:基于短路器,采集各种异常事件,报错,超时,reject,短路,熔断,一定时间范围内就不允许访问了,直接降级,自动恢复的机制
- 降级:报错,超时,reject,熔断,降级,服务提供容错的机制
- 限流:在你的服务里面,通过线程池,或者信号量,限制对某个后端的服务或资源的访问量,避免从你的服务这里过去太多的流量,打死某个资源
- 超时:避免某个依赖服务性能过差,导致大量的线程hang住去调用那个服务,会导致你的服务本身性能也比较差
hystrix的高阶知识
- request collapser,请求合并技术
- fail-fast和fail-slient,高阶容错模式
- static fallback和stubbed fallback,高阶降级模式
- 嵌套command实现的发送网络请求的降级模式
- 基于facade command的多级降级模式
- request cache的手动清理
- 生产环境中的线程池大小以及timeout配置优化经验
- 线程池的自动化动态扩容与缩容技术
- hystrix的metric高阶配置
- 基于hystrix dashboard的可视化分布式系统监控
- 生产环境中的hystrix工程运维经验