Storm介绍与集群部署实战
此为龙果学院课程笔记,记录以供以后翻看
java系统跟大数据技术的关系
- 大数据不仅仅只是大数据工程师要关注的东西
- 大数据也是Java程序员在构建各类系统的时候一种全新的思维,以及架构理念,比如Storm,Hive,Spark,ZooKeeper,HBase,Elasticsearch,等等
Storm:实时缓存热点数据统计->缓存预热->缓存热点数据自动降级
Hive:Hadoop生态栈里面,做数据仓库的一个系统,高并发访问下,海量请求日志的批量统计分析,日报周报月报,接口调用情况,业务使用情况,等等
Spark:离线批量数据处理,比如从DB中一次性批量处理几亿数据,清洗和处理后写入Redis中供后续的系统使用,大型互联网公司的用户相关数据
ZooKeeper:分布式系统的协调,分布式锁,分布式选举->高可用HA架构,轻量级元数据存储
HBase:海量数据的在线存储和简单查询,替代MySQL分库分表,提供更好的伸缩性
Elasticsearch:海量数据的复杂检索以及搜索引擎的构建,支撑有大量数据的各种企业信息化系统的搜索引擎,电商/新闻等网站的搜索引擎,等等
Apache Storm简介
Storm是一个分布式的,可靠的,容错的数据流处理系统。是非常流行的实时计算框架,也非常成熟。
- 支撑各种实时类的项目场景:实时处理消息以及更新数据库,基于最基础的实时计算语义和API(实时数据处理领域);对实时的数据流持续的进行查询或计算,同时将最新的计算结果持续的推送给客户端展示,同样基于最基础的实时计算语义和API(实时数据分析领域);对耗时的查询进行并行化,基于DRPC,即分布式RPC调用,单表30天数据,并行化,每个进程查询一天数据,最后组装结果
- 高度的可伸缩性:如果要扩容,直接加机器,调整storm计算作业的并行度就可以了,storm会自动部署更多的进程和线程到其他的机器上去,无缝快速扩容
- 数据不丢失的保证:storm的消息可靠机制开启后,可以保证一条数据都不丢
- 超强的健壮性:从历史经验来看,storm比hadoop、spark等大数据类系统,健壮的多的多,因为元数据全部放zookeeper,不在内存中,随便挂都不要紧
- 使用的便捷性:核心语义非常的简单,开发起来效率很高
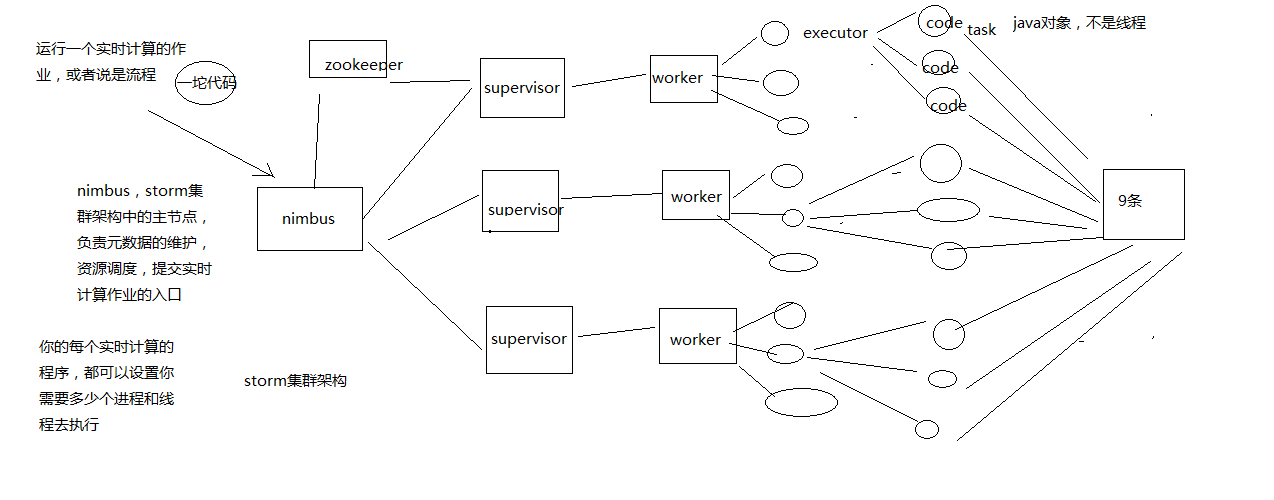
Storm的集群架构以及核心概念
Nimbus,Supervisor,ZooKeeper,Worker,Executor,Task
Topology,Spout,Bolt,Tuple,Stream
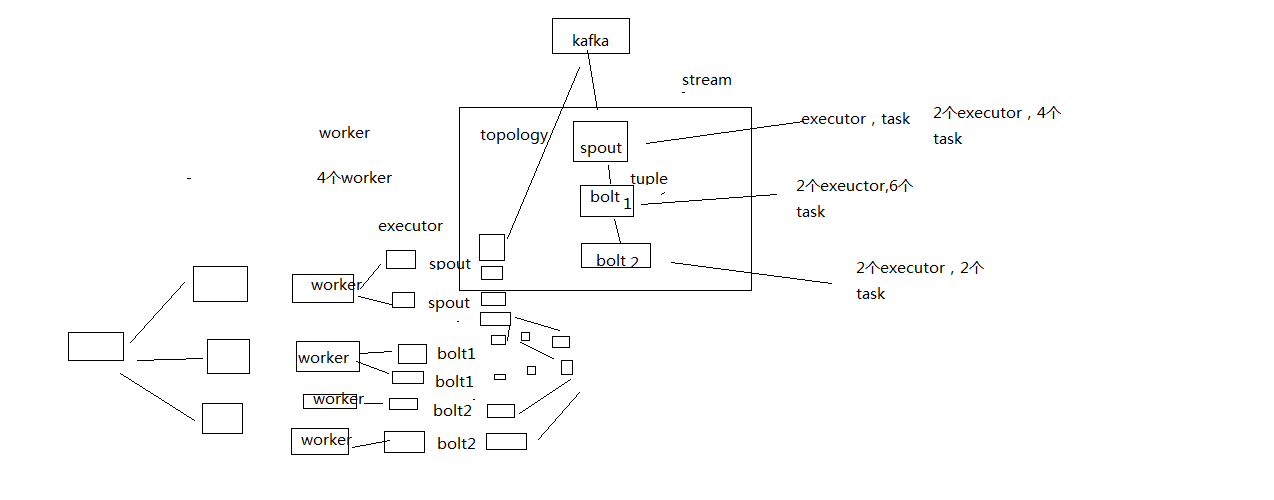
拓扑:务虚的一个概念
Spout:数据源的一个代码组件,就是我们可以实现一个spout接口,写一个java类,在这个spout代码中,我们可以自己尝试去数据源获取数据,比如说从kafka中消费数据
bolt:一个业务处理的代码组件,spout会将数据传送给bolt,各种bolt还可以串联成一个计算链条,java类实现了一个bolt接口
一堆spout+bolt,就会组成一个topology,就是一个拓扑,实时计算作业,spout+bolt,一个拓扑涵盖数据源获取/生产+数据处理的所有的代码逻辑,topology
tuple:就是一条数据,每条数据都会被封装在tuple中,在多个spout和bolt之间传递
stream:就是一个流,务虚的一个概念,抽象的概念,源源不断过来的tuple,就组成了一条数据流
Spout和bolt组件会向Nimbus请求资源,通过Supervisor分配到不同的worker,然后开启多个task执行任务。
Storm组件
在Storm集群中,有两类节点:主节点master node和工作节点worker nodes。主节点运行Nimbus守护进程,这个守护进程负责在集群中分发代码,为工作节点分配任务,并监控故障。Supervisor守护进程作为拓扑的一部分运行在工作节点上。一个Storm拓扑结构在不同的机器上运行着众多的工作节点。每个工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或者集群。
Zookeeper
Zookeeper是完成Supervisor和Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装进Storm中的“topology”。topology则是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接的图。
Spout
Spout从来源处读取数据并放入topology。Spout分成可靠和不可靠两种;当Storm接收失败时,可靠的Spout会对tuple(元组,数据项组成的列表)进行重发;而不可靠的Spout不会考虑接收成功与否只发射一次。而Spout中最主要的方法就是nextTuple(),该方法会发射一个新的tuple到topology,如果没有新tuple发射则会简单的返回。
Bolt
Topology中所有的处理都由Bolt完成。Bolt从Spout中接收数据并进行处理,如果遇到复杂流的处理也可能将tuple发送给另一个Bolt进行处理。而Bolt中最重要的方法是execute(),以新的tuple作为参数接收。不管是Spout还是Bolt,如果将tuple发射成多个流,这些流都可以通过declareStream()来声明。
Storm的并行度以及流分组
并行度:Worker->Executor->Task,没错,是Task
流分组:Task与Task之间的数据流向关系
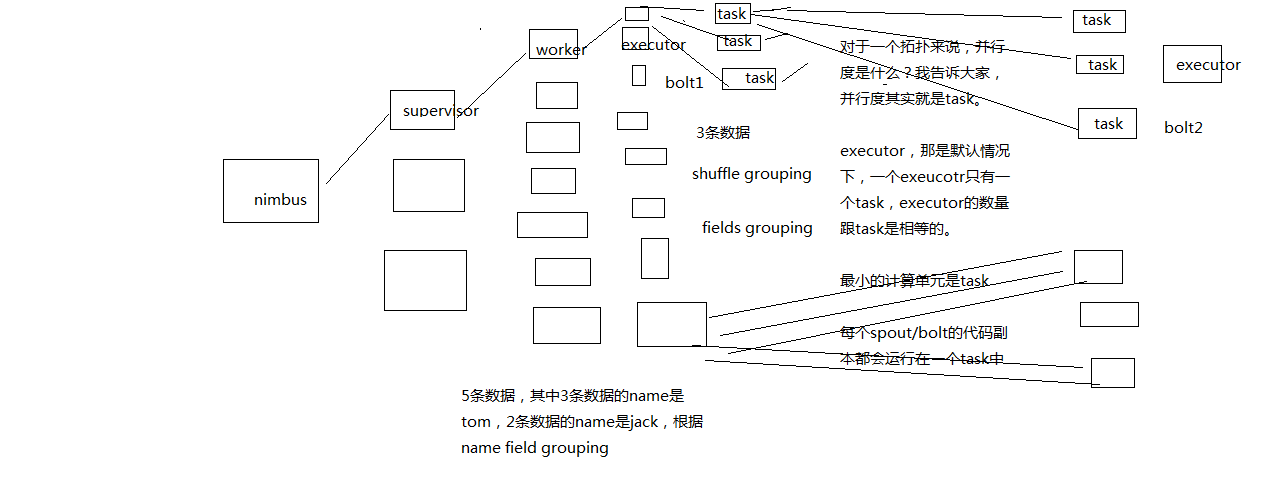
Stream Grouping定义了一个流在Bolt任务中如何被切分。
Shuffle grouping:随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
Fields grouping:根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
Partial Key grouping:根据指定字段分割数据流,并分组。类似Fields grouping。
All grouping:tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
Global grouping:全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
None grouping:无需关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
Direct grouping:这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
Local or shuffle grouping:如果目标bolt有一个或多个任务在同一工作进程,tuples 会打乱这些进程内的任务。否则,这就像一个正常的 Shuffle grouping。
一般只用Shuffle grouping和Fields grouping。
helloworld
https://github.com/sail-y/storm-helloworld
集群部署
拷贝apache-storm-1.1.0.tar.gz到/usr/local目录下,解压。
1 | /usr/local |
配置环境变量:
1 | vi ~/.bashrc |
修改storm配置文件:
1 | mkdir /var/storm |
把另外两台机器也部署上:
1 | scp ~/.bashrc root@192.168.2.202:~/ |
记得source一下和创建/var/storm的目录。
在201上的nimbus:storm nimbus >/dev/null 2>&1 &
3个节点都启动supervisor :storm supervisor >/dev/null 2>&1 &
201启动storm ui:storm ui >/dev/null 2>&1 &
3个节点都启动logviewer:storm logviewer >/dev/null 2>&1 &
用jps检查是否已经启动。
1 | jps |
访问Storm UI查看集群状态:http://192.168.2.201:8080/index.html
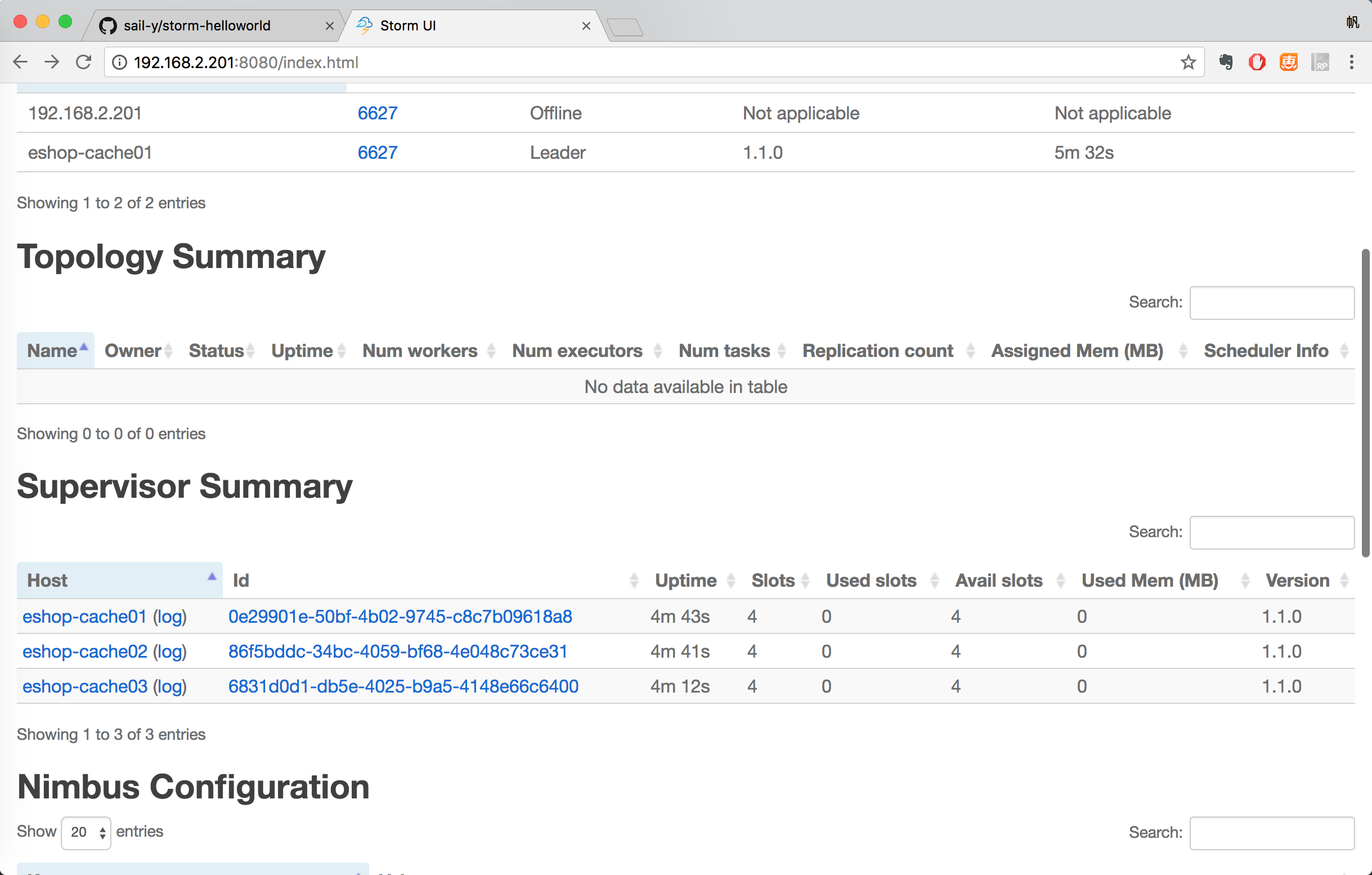
提交作业到storm集群来运行
先将上面的项目打包
mvn clean package
将打包好的storm-helloworld-1.0-SNAPSHOT.jar上传到201的/usr/local目录下。
然后执行命令提交作业到storm集群。
1 | storm jar /usr/local/storm-helloworld-1.0-SNAPSHOT.jar com.roncoo.eshop.storm.WorkCountTopology WorkCountTopology |
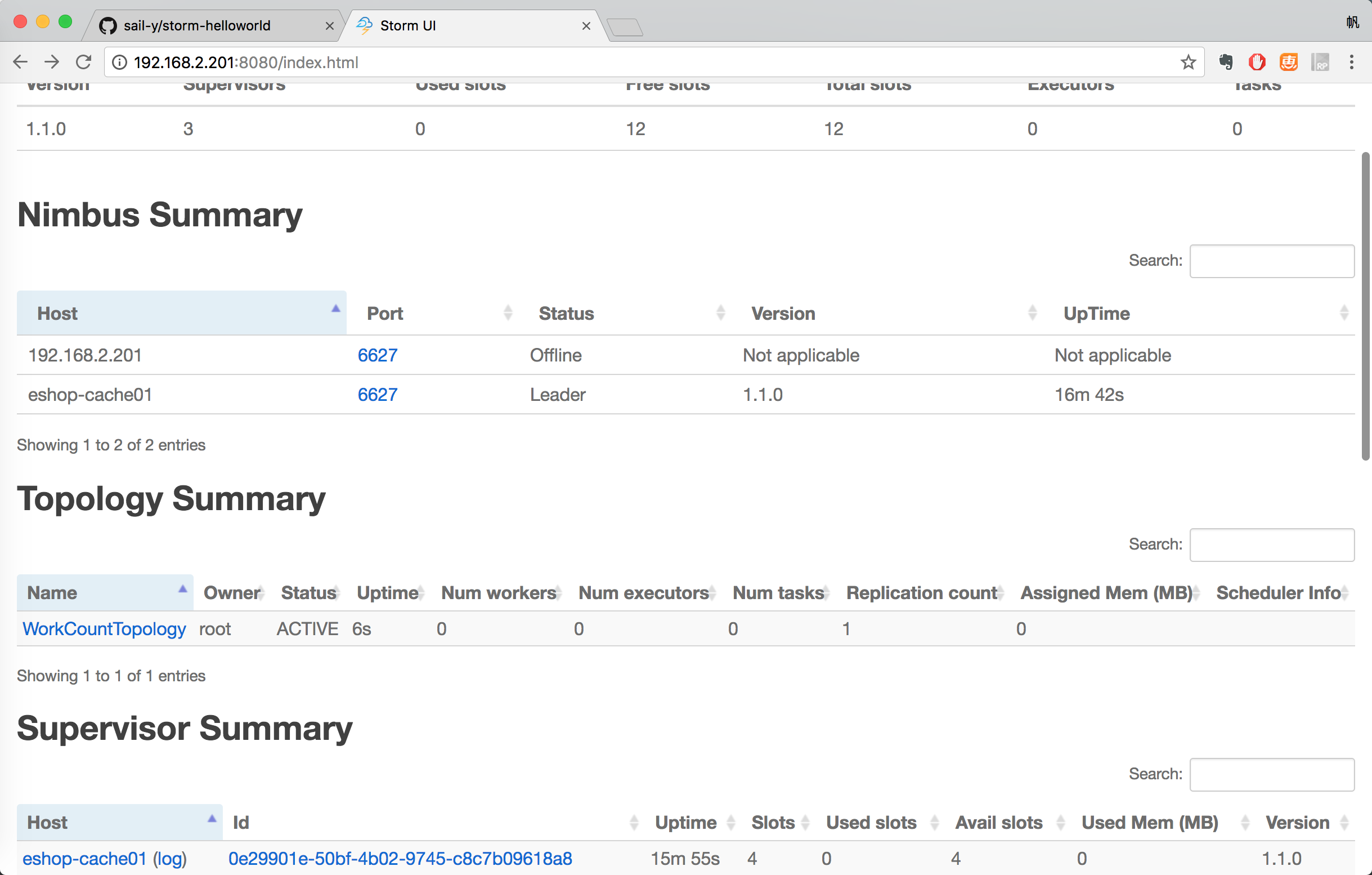
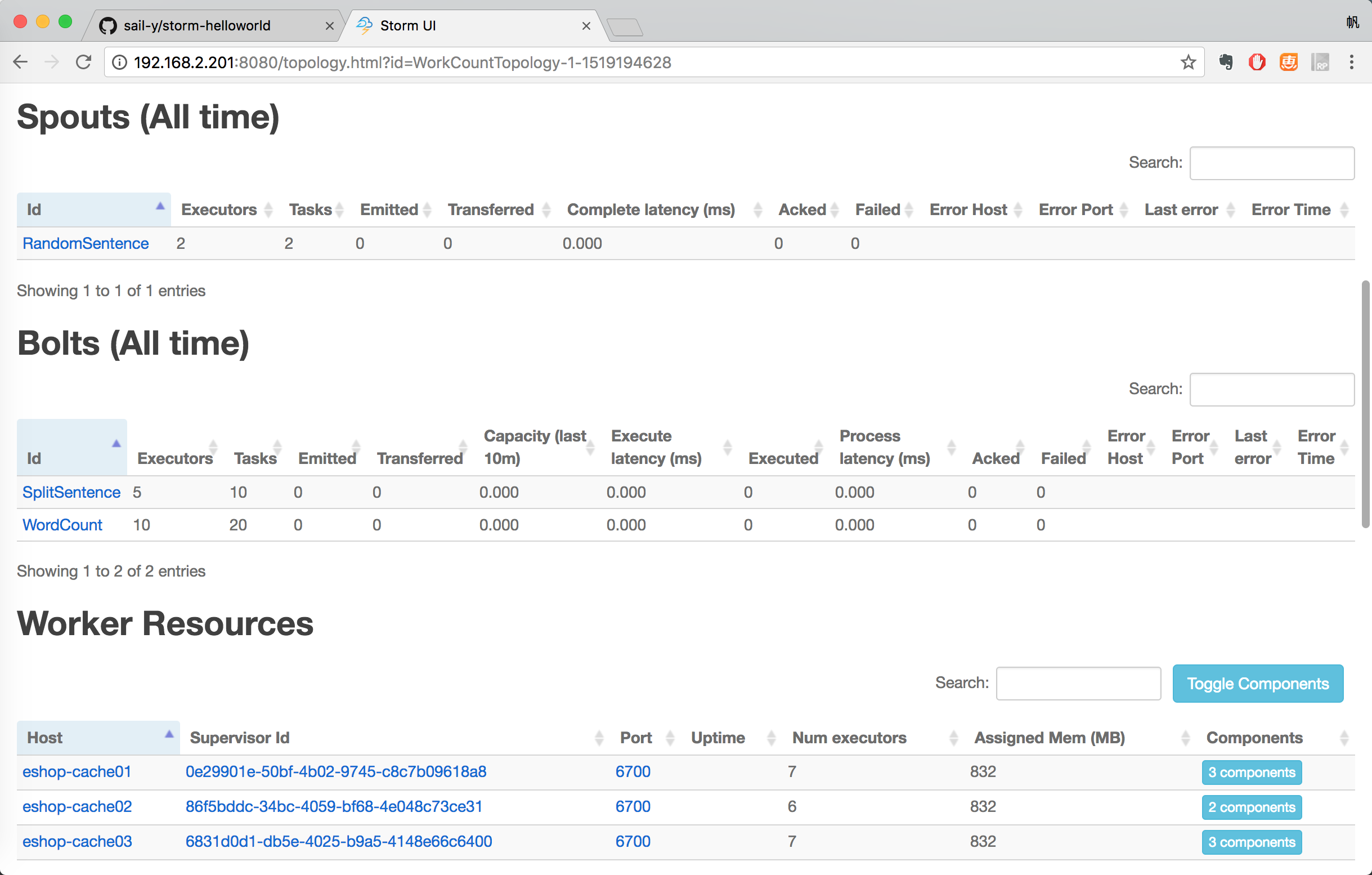
如何kill掉一个topology:
1 | storm kill WorkCountTopology |
总结
本文系统讲解了技术要点,通过学习掌握核心知识和实践方法。