高可用缓存架构实战 04:多级缓存架构设计与实现
此为龙果学院课程笔记,记录以供以后翻看
概述
本文系统讲解Redis缓存架构的核心技术,包括持久化配置、高可用方案和最佳实践。
上亿流量的商品详情页系统的多级缓存架构
很多人以为做个缓存其实就是用一下redis访问一下就可以了,这只是简单的缓存使用方式。做复杂的缓存,支撑电商等复杂的场景下的高并发的缓存,遇到的问题非常非常之多,绝对不是说简单的访问一下redis就可以了。
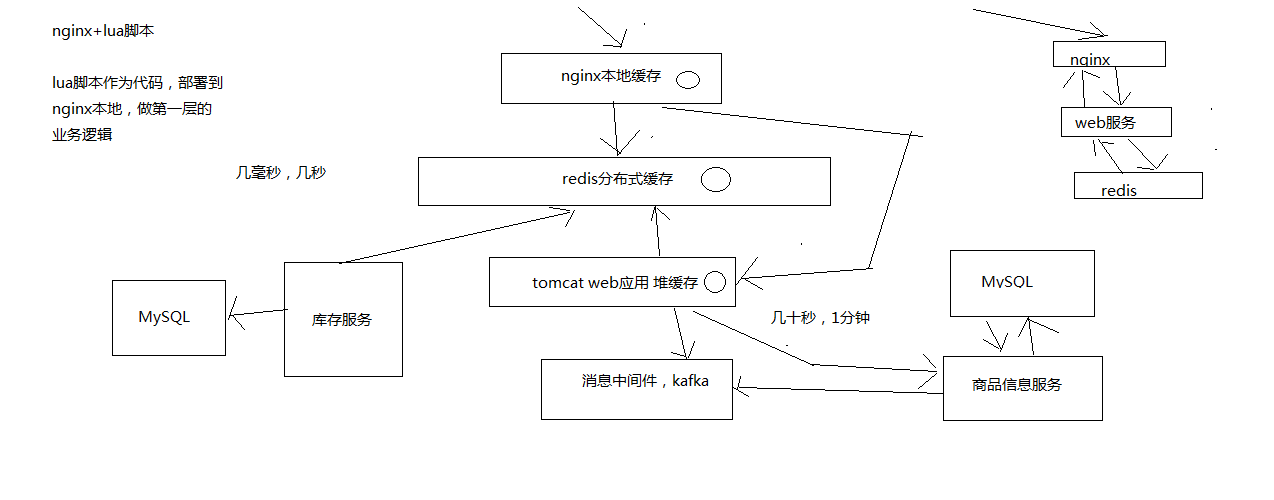
通常采用三级缓存:nginx本地缓存+redis分布式缓存+tomcat堆缓存的多级缓存架构
时效性要求非常高的数据:库存
一般来说,显示的库存都是时效性要求会相对高一些,因为随着商品的不断的交易,库存会不断的变化。当然,我们就希望当库存变化的时候,尽可能更快将库存显示到页面上去,而不是说等了很长时间,库存才反应到页面上去。
时效性要求不高的数据:商品的基本信息(名称. 颜色. 版本. 规格参数,等等),时效性要求不高的数据,就还好,比如说你现在改变了商品的名称,稍微晚个几分钟反应到商品页面上,也是可以接受的。
商品价格/库存等时效性要求高的数据,这种数据不多,相关的服务系统每次发生了变更的时候,直接采取数据库和redis缓存双写的方案,这样缓存的时效性最高。
商品基本信息等时效性不高的数据,而且种类繁多,来自多种不同的系统,采取MQ异步通知的方式,写一个数据生产服务,监听MQ消息,然后异步拉取服务的数据,更新tomcat jvm缓存+redis缓存。
流程:nginx+lua脚本做页面动态生成的工作,每次请求过来,优先从nginx本地缓存中提取各种数据,结合页面模板,生成需要的页面。如果nginx本地缓存过期了,那么就从nginx到redis中去拉取数据,更新到nginx本地。如果redis中也被LRU算法清理掉了,那么就从nginx走http接口到后端的服务中拉取数据,数据生产服务中,先在本地tomcat里的jvm堆缓存(ehcache)中找,如果也被LRU清理掉了,那么就重新发送请求到源头的服务中去拉取数据,然后再次更新tomcat堆内存缓存+redis缓存,并返回数据给nginx,nginx缓存到本地。
多级缓存架构中每一层的意义
nginx本地缓存,抗的是热数据的高并发访问,一般来说,商品的购买总是有热点的,比如每天购买iphone. nike. 海尔等知名品牌的东西的人,总是比较多的。这些热数据,由于经常被访问,利用nginx本地缓存,所以可以被锁定在nginx的本地缓存内。大量的热数据的访问,就会被保留在nginx本地缓存内,那么对这些热数据的大量访问,就直接走nginx就可以了。那么大量的访问,直接就可以走到nginx就行了,不需要走后续的各种网络开销了。
redis分布式大规模缓存,抗的是很高的离散访问,支撑海量的数据,高并发的访问,高可用的服务。redis缓存最大量最完整的数据,可能1T+数据; 支撑高并发的访问,QPS最高到几十万; 可用性需要非常好,提供非常稳定的服务。nginx本地内存有限,也就能cache住部分热数据,除了各种iphone. nike等热数据,其他相对不那么热的数据,可能流量会经常走到redis那里。利用redis cluster的多master写入,横向扩容,1T+以上海量数据支持,几十万的读写QPS,99.99%高可用性都没有问题,那么就可以抗住大量的离散访问请求。
tomcat jvm堆内存缓存,主要是抗redis大规模灾难的情况,如果redis出现了大规模的宕机,导致nginx大量流量直接涌入数据生产服务,那么最后的tomcat堆内存缓存至少可以再抗一下,不至于让数据库直接裸奔。同时tomcat jvm堆内存缓存,也可以抗住redis没有cache住的最后那少量的部分缓存。
多级缓存架构项目实例源码
时效性要求不高的数据,采取的是异步更新缓存的策略。缓存数据生产服务,监听一个消息队列,然后数据源服务(商品信息管理服务)发生了数据变更之后,就将数据变更的消息推送到消息队列中。缓存数据生产服务可以去消费这个数据变更的消息,然后根据消息的指示提取一些参数,然后调用对应的数据源服务的接口拉取数据,这个时候一般是从mysql库中拉取的。
这里消息中间件,我们使用kafka,zookeeper+kafka集群的安装部署
项目源码地址:https://github.com/sail-y/eshop-cache
Nginx层缓存
前面三层缓存架构中的本地堆缓存+redis分布式缓存都做好了,接下来就要来做三级缓存中的nginx那一层的缓存了。一般默认会部署多个nginx,在里面都会放一些缓存,默认情况下,此时缓存命中率是比较低的,因为流量会均分。
如何提升缓存命中率?
分发层+应用层,双层nginx。
分发层nginx,负责流量分发的逻辑和策略,它可以用lua脚本开发一些规则,比如根据productId去进行hash,然后对后端的nginx数量取模,将某一个商品的访问的请求,就固定路由到一个nginx后端服务器上去,保证只会从redis中获取一次缓存数据,再次请求全都是走nginx本地缓存了。
后端的nginx服务器,就称之为应用服务器; 最前端的nginx服务器,被称之为分发服务器。看似很简单,其实很有用,在实际的生产环境中,可以大幅度提升你的nginx本地缓存这一层的命中率,大幅度减少redis后端的压力,提升性能。
这里会采用OpenResty的方式去部署nginx,而且会写一个nginx+lua开发的一个hello world。
部署第一个nginx,作为应用层nginx
我这里部署到我机器上192.168.2.201,教程参考http://jinnianshilongnian.iteye.com/blog/2186270
部署openresty
1 | yum install -y readline-devel pcre-devel openssl-devel gcc |
启动nginx: /usr/servers/nginx/sbin/nginx
nginx+lua开发的hello world
vi /usr/servers/nginx/conf/nginx.conf
在http部分添加:
1 | lua_package_path "/usr/servers/lualib/?.lua;;"; |
/usr/servers/nginx/conf下,创建一个lua.conf
1 | server { |
在nginx.conf的http部分添加:
include lua.conf;
验证配置是否正确:
/usr/servers/nginx/sbin/nginx -t
在lua.conf的server部分添加:
1 | location /lua { |
验证配置是否正确:
/usr/servers/nginx/sbin/nginx -t
重新nginx加载配置
/usr/servers/nginx/sbin/nginx -s reload
成功输出 hello world
接下来替换成lua脚本文件执行
1 | mkdir /usr/servers/nginx/conf/lua/ |
修改lua.conf
1 | location /lua { |
验证配置是否正确:
/usr/servers/nginx/sbin/nginx -t
重新nginx加载配置
/usr/servers/nginx/sbin/nginx -s reload
查看异常日志
tail -f /usr/servers/nginx/logs/error.log
工程化的nginx+lua项目结构
刚才只是写了一个hello world,在正式的项目中,脚本的目录结构一般是下面这样:
1 | hello |
放在/usr/hello目录下,不会放在nginx所在文件夹里。
配置如下:
1 | mkdir -p /usr/hello/lua |
修改nginx.conf
1 | vi /usr/servers/nginx/conf/nginx.conf |
验证配置是否正确:
/usr/servers/nginx/sbin/nginx -t
重新nginx加载配置
/usr/servers/nginx/sbin/nginx -s reload
如法炮制,在另外一个机器上,也用OpenResty部署一个nginx。
开发和部署流量分发层
我在eshop-cache02和eshop-cache03上都部署好了openresty。现在用eshop-cache01和eshop-cache02作为应用层nginx服务器,用eshop-cache03作为分发层nginx。
现在在eshop-cache03,也就是分发层nginx中,编写lua脚本,完成基于商品id的流量分发策略:
- 获取请求参数,比如productId
- 对productId进行hash
- hash值对应用服务器数量取模,获取到一个应用服务器
- 利用http发送请求到应用层nginx
- 获取响应后返回
这个就是基于商品id的定向流量分发的策略,lua脚本来编写和实现。作为一个流量分发的nginx,会发送http请求到后端的应用nginx上面去,所以要先引入lua http lib包。
1 | cd /usr/hello/lualib/resty/ |
然后我们编辑流量分发的代码:
1 | local uri_args = ngx.req.get_uri_args() |
访问测试:
1 | /usr/servers/nginx/sbin/nginx -s reload |
基于商品id的定向流量分发策略的lua脚本就开发完了。经过测试可以看到,如果请求的是固定的某一个商品,那么就一定会将流量分到固定的一个应用nginx上面去。
基于nginx+lua+java完成多级缓存架构的核心业务逻辑
上面做了流量分发的demo测试,Java层级的缓存开发,接下来把他们对接起来,正式编写分发层和应用层的脚本。
eshop-cache03机器上修改流量分发层配置和lua脚本:
1 | vi hello.conf |
修改应用层配置和lua脚本:
应用nginx的lua脚本接收到请求
获取请求参数中的商品id,以及商品店铺id
根据商品id和商品店铺id,在nginx本地缓存中尝试获取数据
如果在nginx本地缓存中没有获取到数据,那么就到redis分布式缓存中获取数据,如果获取到了数据,还要设置到nginx本地缓存中
这里有个问题,建议不要用nginx+lua直接去获取redis数据。因为openresty没有太好的redis cluster的支持包,所以建议是发送http请求到缓存数据生产服务,由该服务提供一个http接口。缓存数生产服务可以基于redis cluster api从redis中直接获取数据,并返回给nginx。
如果缓存数据生产服务没有在redis分布式缓存中没有获取到数据,那么就在自己本地ehcache中获取数据,返回数据给nginx,也要设置到nginx本地缓存中
如果ehcache本地缓存都没有数据,那么就需要去原始的服务中拉去数据,该服务会从mysql中查询,拉去到数据之后,返回给nginx,并重新设置到ehcache和redis中
nginx最终利用获取到的数据,动态渲染网页模板
因为应用层也要访问http接口,所以也需要部署http依赖和模板的依赖
1
2
3
4
5
6
7
8cd /usr/hello/lualib/resty/
wget https://raw.githubusercontent.com/pintsized/lua-resty-http/ master/lib/resty/http_headers.lua
wget https://raw.githubusercontent.com/pintsized/lua-resty-http/master/lib/resty/http.lua
cd /usr/hello/lualib/resty/
wget https://raw.githubusercontent.com/bungle/lua-resty-template/master/lib/resty/template.lua
mkdir /usr/hello/lualib/resty/html
cd /usr/hello/lualib/resty/html
wget https://raw.githubusercontent.com/bungle/lua-resty-template/master/lib/resty/template/html.lua在hello.conf的server中配置模板位置
1
2set $template_location "/templates";
set $template_root "/usr/hello/templates";编辑要显示的模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24mkdir /usr/hello/templates
cd /usr/hello/templates
vi product.html
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>商品详情页</title>
</head>
<body>
商品id: {* productId *}<br/>
商品名称: {* productName *}<br/>
商品图片列表: {* productPictureList *}<br/>
商品规格: {* productSpecification *}<br/>
商品售后服务: {* productService *}<br/>
商品颜色: {* productColor *}<br/>
商品大小: {* productSize *}<br/>
店铺id: {* shopId *}<br/>
店铺名称: {* shopName *}<br/>
店铺评级: {* shopLevel *}<br/>
店铺好评率: {* shopGoodCommentRate *}<br/>
</body>
</html>将渲染后的网页模板作为http响应,返回给分发层nginx
在
nginx.conf的http模块里添加:1
2# 添加nginx本地缓存的支持
lua_shared_dict my_cache 128m;修改
hello.conf:1
2
3
4
5# 添加路由
location /product {
default_type 'text/html';
content_by_lua_file /usr/hello/lua/product.lua;
}修改lua/product.lua脚本,注意192.168.2.171是我本机的ip,启动了Java项目:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60vi lua/product.lua
local uri_args = ngx.req.get_uri_args()
local productId = uri_args["productId"]
local shopId = uri_args["shopId"]
local cache_ngx = ngx.shared.my_cache
local productCacheKey = "product_info_"..productId
local shopCacheKey = "shop_info_"..shopId
local productCache = cache_ngx:get(productCacheKey)
local shopCache = cache_ngx:get(shopCacheKey)
if productCache == "" or productCache == nil then
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri("http://192.168.2.171:8080",{
method = "GET",
path = "/getProductInfo?productId="..productId
})
productCache = resp.body
cache_ngx:set(productCacheKey, productCache, 10 * 60)
end
if shopCache == "" or shopCache == nil then
local http = require("resty.http")
local httpc = http.new()
local resp, err = httpc:request_uri("http://192.168.2.171:8080",{
method = "GET",
path = "/getShopInfo?shopId="..shopId
})
shopCache = resp.body
cache_ngx:set(shopCacheKey, shopCache, 10 * 60)
end
local cjson = require("cjson")
local productCacheJSON = cjson.decode(productCache)
local shopCacheJSON = cjson.decode(shopCache)
local context = {
productId = productCacheJSON.id,
productName = productCacheJSON.name,
productPrice = productCacheJSON.price,
productPictureList = productCacheJSON.pictureList,
productSpecification = productCacheJSON.specification,
productService = productCacheJSON.service,
productColor = productCacheJSON.color,
productSize = productCacheJSON.size,
shopId = shopCacheJSON.id,
shopName = shopCacheJSON.name,
shopLevel = shopCacheJSON.level,
shopGoodCommentRate = shopCacheJSON.goodCommentRate
}
local template = require("resty.template")
template.render("product.html", context)写到这里,应该去把java项目里的2个接口给补充一下。还是之前的项目:https://github.com/sail-y/eshop-cache
分布式重建缓存的并发冲突问题
之前在Java代码里会先去redis里面取数据,如果redis取不到,就会去ehcache里面取,如果还是取不到,就需要重建缓存了。
但是重建缓存有一个问题,因为我们的服务可能是多实例的,虽然在nginx层我们通过流量分发将请求通过id分发到了不同的nginx应用层上。那么到了接口服务层,可能多次请求访问的是不同的实例,那么可能会导致多个机器去重建读取相同的数据,然后写入缓存中,这就有了分布式重建缓存的并发冲突问题。
问题就是可能2个实例获取到的数据快照不一样,但是新数据先写入缓存,如果这个时候另外一个实例的缓存后写入,就有问题了。
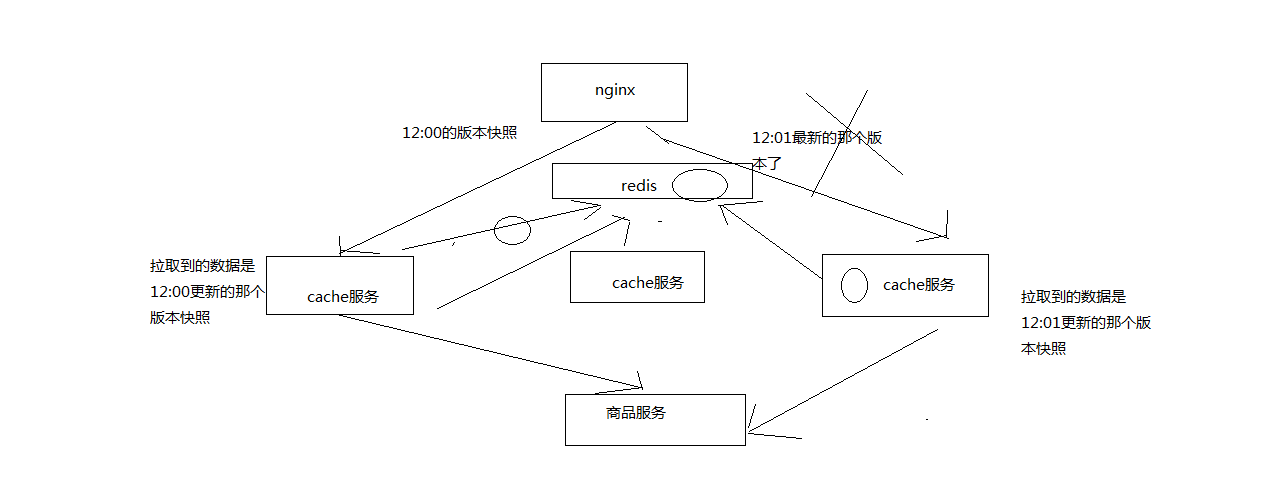
这个问题有好几种解决方案:
一样的在应用层对id进行取模然后固定分发到不同的服务实例上
将更新缓存的请求发送到同一个分区的kafka消息中
一般来讲,每个服务实例都会监听kafka一个topic的某一个分区,所以具体去哪一个分区也得取模,保证是同一个实例消费到更新的请求。但问题是在nginx算出来的hash取模可能与kafka生产者的hash策略算出来的分区可能并不一致,还是可能有并发冲突问题。
基于zookeeper分布式锁的解决方案
分布式锁,如果你有多个机器在访问同一个共享资源,加个锁让多个分布式的机器在访问共享资源的时候串行起来。
zk分布式锁的解决并发冲突的方案
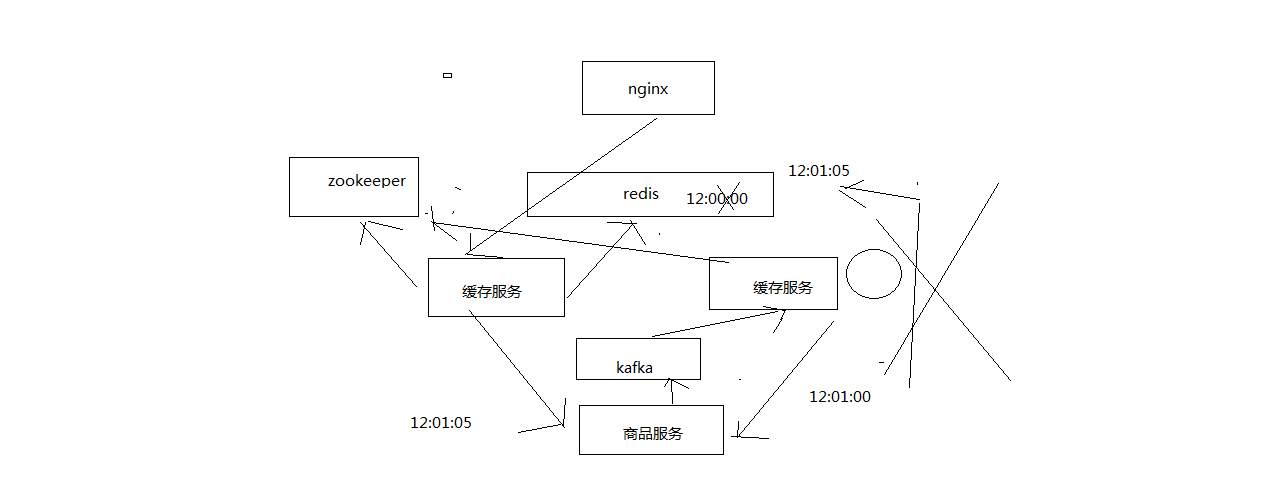
- 变更缓存重建以及空缓存请求重建,更新redis之前,都需要先获取对应商品id的分布式锁
- 拿到分布式锁之后,需要根据时间版本去比较一下,如果自己的版本新于redis中的版本,那么就更新,否则就不更新
- 如果拿不到分布式锁,那么就等待,不断轮询等待,直到自己获取到分布式的锁
方案源码实现:https://github.com/sail-y/eshop-cache
ZooKeeperSession.java
经典的缓存+数据库读写的模式(cache aside pattern)
读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应
更新的时候,先删除缓存,然后再更新数据库
为什么是删除缓存,而不是更新缓存呢?
原因很简单,很多时候,复杂点的缓存的场景,因为缓存有的时候,不简单是数据库中直接取出来的值。比如商品详情页的系统,修改库存,只是修改了某个表的某些字段,但是要真正把这个影响的最终的库存计算出来,可能还需要从其他表查询一些数据,然后进行一些复杂的运算,才能最终计算出现在最新的库存是多少,然后才能将库存更新到缓存中去。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据,并进行运算,才能计算出缓存最新的值的,更新缓存的代价是很高的。还有一个问题就是,是不是每次修改数据库的时候,都一定要将其对应的缓存去跟新一份?也许有的场景是这样的,但是对于比较复杂的缓存数据计算的场景,就不是这样了。举个例子,一个缓存涉及的表的字段,在1分钟内就修改了20次,或者是100次,那么缓存更新20次,100次; 但是这个缓存在1分钟内就被读取了1次,系统有大量的冷数据,28法则,20%的数据,占用了80%的访问量。实际上,如果你只是删除缓存的话,那么1分钟内,访问的时候再计算,这个缓存不过就重新计算一次而已,开销大幅度降低。每次数据过来,就只是删除缓存,然后修改数据库,如果这个缓存,在1分钟内只是被访问了1次,那么只有那1次,缓存是要被重新计算的,用缓存才去算缓存。其实删除缓存,而不是更新缓存,就是一个lazy计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。
缓存+数据库双写不一致问题分析
最初级的缓存不一致问题以及解决方案
问题:先修改数据库,再删除缓存,如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据出现不一致
解决思路:
先删除缓存,再修改数据库,如果删除缓存成功了,如果修改数据库失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致,因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中,数据变更的程序完成了数据库的修改,这个时候数据库和缓存中的数据不一样了。
为什么上亿流量高并发场景下,缓存会出现这个问题?
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就1万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况,高并发了以后,问题是很多的。
解决方案:
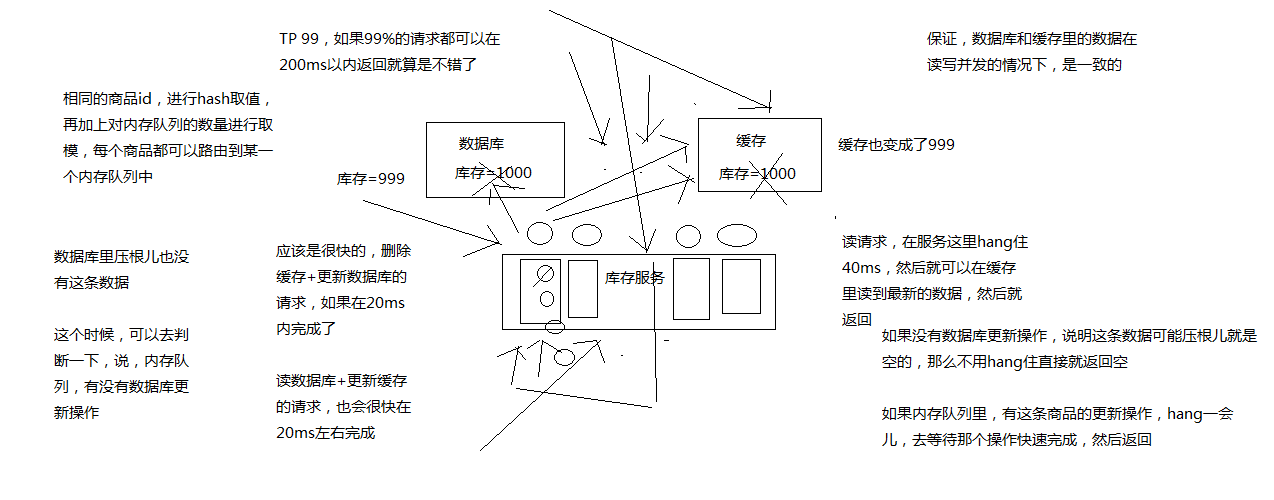
**数据库与缓存更新与读取操作进行异步串行化。**更新数据的时候,根据数据的唯一标识(例如hash值取模),将操作路由之后,发送到一个jvm内部的队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个jvm内部的队列中。一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回; 如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题
读请求长时阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。该解决方案,最大的风险点在于可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库,所以务必通过一些模拟真实的测试,看看更新数据的频繁是怎样的。
另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。如果一个内存队列里居然会挤压100个商品的库存修改操作,每个库存修改操作要耗费10ms去完成,那么最后一个商品的读请求,可能等待10 * 100 = 1000ms = 1s后,才能得到数据,这个时候就导致读请求的长时阻塞。
一定要做根据实际业务系统的运行情况,去进行一些压力测试和模拟线上环境,去看看最繁忙的时候,内存队列可能会挤压多少更新操作,可能会导致最后一个更新操作对应的读请求会hang多少时间,如果你计算过后,哪怕是最繁忙的时候,积压10个更新操作,最多等待200ms,那还可以。如果一个内存队列可能积压的更新操作特别多,那么就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
一般来说数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的,针对读高并发,读缓存架构的项目,一般写请求相对读来说,是非常非常少的,每秒的QPS能到几百就不错了。比如500/s的写操作,拆成5份,每200ms就是100个写操作,单机器一般20个内存队列,每个内存队列,可能就积压5个写操作,每个写操作性能测试后,一般在20ms左右就完成。如果写QPS扩大10倍,但是经过刚才的测算,就知道,单机支撑写QPS几百没问题,那么就扩容机器,扩容10倍的机器,10台机器,每个机器20个队列,200个队列。
大部分的情况下,应该是大量的读请求过来,都是直接走缓存取到数据的。少量情况下,可能遇到读跟数据更新冲突的情况,如上所述,那么此时更新操作如果先入队列,之后可能会瞬间来了对这个数据大量的读请求,但是因为做了去重的优化,所以也就一个更新缓存的操作跟在它后面,等数据更新完了,读请求触发的缓存更新操作也完成,然后临时等待的读请求全部可以读到缓存中的数据。
读请求并发量过高
还必须做好压力测试,确保恰巧碰上上述情况的时候,还有另一个风险,就是突然间大量读请求会在几十毫秒的延时hang在服务上,看服务能不能抗的住,需要多少机器才能抗住最大的极限情况的峰值。但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。按1:99的比例计算读和写的请求,每秒5万的读QPS,可能只有500次更新操作,如果一秒有500的写QPS,那么要测算好,可能写操作影响的数据有500条,这500条数据在缓存中失效后可能导致多少读请求发送读请求到库存服务来要求更新缓存。一般来说这个比例在1:1,1:2,1:3之内,例如500条缓存数据失效导致每秒钟有1000个读请求会hang在库存服务上,每个读请求最多hang200ms就会返回。在同一时间最多hang住的可能也就是单机200个读请求,单机hang200个读请求,还是ok的。
多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证,执行数据更新操作,以及执行缓存更新操作的请求,都通过nginx服务器路由到相同的服务实例上。
热点商品的路由问题,导致请求的倾斜
万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能造成某台机器的压力过大。因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是特别大,但是的确可能某些机器的负载会高一些。
复杂的数据库+缓存双写一致保障方案项目实例源码
https://github.com/sail-y/eshop-inventory
总结
本文系统讲解了Redis缓存架构的关键技术要点。通过合理的缓存设计和持久化配置,可以有效提升系统性能和数据安全性。建议根据实际业务场景选择合适的缓存策略,并做好监控和运维工作。
关键要点
- 理解缓存架构的核心设计原则
- 掌握Redis持久化机制的配置方法
- 学习企业级缓存方案的最佳实践
实践建议
- 根据业务特点选择合适的持久化策略
- 建立完善的监控和告警机制
- 定期备份和演练故障恢复流程