高可用缓存架构实战 02:Redis企业级应用实战
此为龙果学院课程笔记,记录以供以后翻看
Redis企业应用实战
上一篇说了redis的持久化的原理和操作,但是在企业中,持久化到底是怎么去用的呢?企业级的数据备份和各种灾难下的数据恢复,是怎么做的呢?
概述
本文系统讲解Redis缓存架构的核心技术,包括持久化配置、高可用方案和最佳实践。
企业级的持久化的配置策略
在企业中,RDB的生成策略,用默认的配置也差不多。
save 60 10000:如果你希望尽可能确保,RDB最多丢1分钟的数据,那么尽量就是每隔1分钟都生成一个快照,但是低峰期数据量很少,也没必要这样设置。
1分内10000个key发生变更->生成RDB,1分内1000->RDB,这个根据应用和业务的数据量,自己去决定。
AOF一定要打开,fsync配置everysec
auto-aof-rewrite-percentage 100: 就是当前AOF大小膨胀到超过上次100%,上次的两倍就重写。auto-aof-rewrite-min-size 64mb: 至少64m才重写,根据你的数据量来定,可改成16mb,32mb等等。
企业级的数据备份方案
RDB非常适合做冷备,每次生成之后,就不会再有修改了
数据备份方案:
- 写crontab定时调度脚本去做数据备份
- 每小时都copy一份rdb的备份,到一个目录中去,仅仅保留最近48小时的备份
- 每天都保留一份当日的rdb的备份,到一个目录中去,仅仅保留最近1个月的备份
- 每次copy备份的时候,都把太旧的备份给删了
- 每天晚上将当前服务器上所有的数据备份,发送一份到远程的云服务上去
创建一个备份目录:/usr/local/redis,下面的脚本基于这个目录做备份。
每小时copy一次备份,删除48小时前的数据
redis_rdb_copy_hourly.sh
1 |
|
设置定时任务
1 | chmod 777 redis_rdb_copy_hourly.sh |
每天copy一次备份
redis_rdb_copy_daily.sh
1 |
|
设置定时任务
1 | chmod 777 redis_rdb_copy_daily.sh |
数据恢复方案
如果是redis进程挂掉,那么重启redis进程即可,直接基于AOF日志文件恢复数据,上一篇文章在AOF数据恢复那一块说过了,
fsync everysec,最多就丢一秒的数据。如果是redis进程所在机器挂掉,那么重启机器后,尝试重启redis进程,尝试直接基于AOF日志文件进行数据恢复
如果AOF没有破损,可以直接基于AOF恢复的。
AOF append-only,表示是顺序写入的,如果AOF文件破损,那么用redis-check-aof fix命令修复
如果redis当前最新的AOF和RDB文件出现了丢失/损坏,那么可以尝试基于该机器上当前的某个最新的RDB数据副本进行数据恢复,当前最新的AOF和RDB文件都出现了丢失/损坏到无法恢复,一般不是机器的故障,那可能是人为(不小心被删除)。
找到RDB最新的一份备份,小时级的备份可以了,小时级的肯定是最新的,copy到redis里面去,就可以恢复到某一个小时的数据(注意如果存在
appendonly.aof文件,会优先读取appendonly.aof文件)虽然删除了appendonly.aof,但是因为打开了aof持久化,redis就一定会优先基于aof去恢复,即使文件不在,那就会创建一个新的空的aof文件。正确的操作如下:停止redis,关闭aof,拷贝rdb备份,重启redis,确认数据恢复,直接在命令行热修改redis配置,打开aof,这个时候redis就会将内存中的数据对应的日志,写入aof文件中。此时aof和rdb两份数据文件的数据就同步了,在redis-cli中执行
config set appendonly yes热修改配置参数,但是这个时候配置文件中的实际的参数没有被修改,再次停止redis,手动修改配置文件,打开aof的命令,再次重启redis。如果当前机器上的所有RDB文件全部损坏,那么从远程的云服务上拉取最新的RDB快照回来恢复数据
如果是发现有重大的数据错误,比如某个小时上线的程序一下子将数据全部污染了,数据全错了,那么可以选择某个更早的时间点,对数据进行恢复。
如何通过读写分离来承载读请求QPS超过10万+?
redis高并发跟整个系统的高并发之间的关系
做高并发的话,不可避免的是需要把底层的缓存做好。如果是用mysql来做高并发,即使做到了,那么也是通过一系列复杂的分库分表,而且mysql高并发一般用在订单系统,事务要求比较高的地方,QPS能到几万,就已经比较高了。
但是如果要做一些电商的商品详情页,真正的超高并发,QPS上十万,甚至是百万,一秒钟百万的请求量,光是redis是不够的,但是redis是整个大型的缓存架构、支撑高并发的架构中,非常重要的一个环节。
首先,底层的缓存中间件,缓存系统,必须能够支撑的起我们说的那种高并发,其次,再经过良好的整体的缓存架构的设计(多级缓存架构、热点缓存),支撑真正的上十万,甚至上百万的高并发。
redis不能支撑高并发的瓶颈在哪里?
单机是不能支撑高并发的,单机能够承载的QPS大概在上万或者几万不等,根据业务复杂度决定。
如果redis要支撑超过10万+的并发,那应该怎么做?
单机的redis几乎不太可能说QPS超过10万+,除非一些特殊情况,比如你的机器性能特别好,配置特别高,物理机,维护做的特别好,而且你的整体的操作不是太复杂。
读写分离,一般都是用来支撑读高并发的,写的请求是比较少的,可能写请求也就一秒钟几千,一两千,大量的请求都是读,比如一秒钟二十万次读。
读写分离:
主从架构 -> 读写分离 -> 支撑10万+读QPS的架构
架构做成主从架构,一主多从,主负责写,并且将数据同步复制到其他的slave节点,从节点负责读,所有的读请求全部走从节点。
Redis Replication
Redis 支持简单且易用的主从复制(master-slave replication)功能,当主Redis服务器更新数据时能将数据同步到从Redis服务器。
Redis Replication的核心机制
- redis采用异步方式复制数据到slave节点,不过redis 2.8开始,slave node会周期性地确认自己每次复制的数据量
- 一个master node是可以配置多个slave node的
- slave node也可以连接其他的slave node
- slave node做复制的时候,是不会block master node的正常工作的
- slave node在做复制的时候,也不会block对自己的查询操作,它会用旧的数据集来提供服务; 但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了
- slave node主要用来进行横向扩容,做读写分离,扩容的slave node可以提高读的吞吐量
master持久化对于主从架构的安全保障的意义
如果采用了主从架构,那么必须开启master node的持久化。不建议用slave node作为master node的数据热备,因为那样的话,如果你关掉master的持久化,可能在master宕机重启的时候数据是空的,然后可能一经过复制,salve node数据也丢了。
master -> RDB和AOF都关闭了 -> 全部在内存中
master宕机,重启,是没有本地数据可以恢复的,然后就会直接认为自己的数据是空的,master就会将空的数据集同步到slave上去,所有slave的数据全部清空,100%的数据丢失,所以master节点必须要使用持久化机制。
主从架构的核心原理
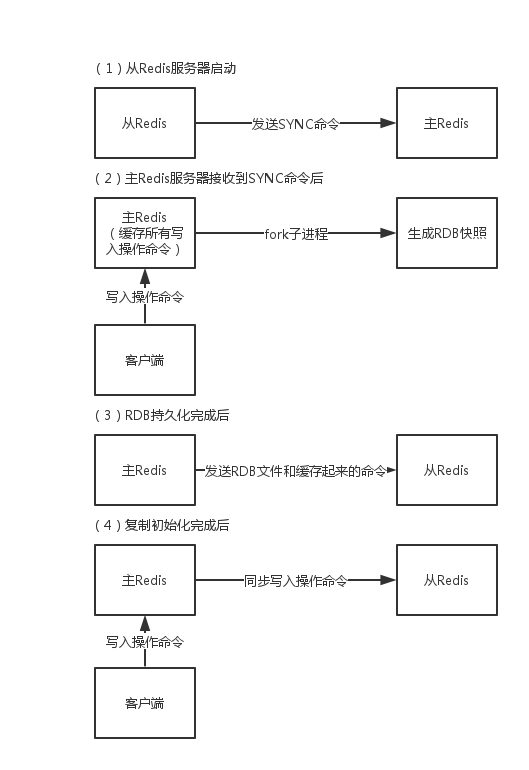
当启动一个slave node的时候,它会发送一个PSYNC命令给master node
如果这时slave node重新连接master node,那么master node仅仅会复制给slave部分缺少的数据; 否则如果是slave node第一次连接master node,那么会触发一次full resynchronization
开始full resynchronization的时候,master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。RDB文件生成完毕之后,master会将这个RDB发送给slave,slave会先写入本地磁盘,然后再从本地磁盘加载到内存中。然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。
slave node如果跟master node有网络故障,断开了连接,会自动重连。master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份数据服务所有slave node。
主从复制的断点续传
从redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份。
master node会在内存中常见一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断掉了,slave会让master从上次的replica offset开始继续复制
但是如果没有找到对应的offset,那么就会执行一次full resynchronization
无磁盘化复制
repl-diskless-sync no
master在内存中直接创建rdb,然后发送给slave,不会在自己本地落地磁盘了
repl-diskless-sync-delay 5
会等待一定时长(上面是5秒)再开始复制,因为要等更多slave重新连接过来。
过期key处理
slave不会过期key,只会等待master过期key。如果master过期了一个key,或者通过LRU淘汰了一个key,那么会模拟一条del命令发送给slave。
深入理解复制机制
再次深入了解一下Redis的配置和复制机制。
复制的完整流程
slave node启动,仅仅保存master node的信息,包括master node的host和ip,但是复制流程没开始。
master的host和ip信息配置:redis.conf -> slaveof配置。slave node内部有个定时任务,每秒检查是否有新的master node要连接和复制,如果发现,就跟master node建立socket网络连接。
slave node发送ping命令给master node。
口令认证,如果master设置了requirepass,那么salve node必须发送masterauth的口令过去进行认证。
master node第一次执行全量复制,将所有数据发给slave node。
master node后续持续将写命令,异步复制给slave node
数据同步相关的核心机制
指的就是第一次slave连接master的时候,执行的全量复制过程里面的一些细节的机制。
master和slave都会维护一个offset
master会在自身不断累加offset,slave也会在自身不断累加offset,slave每秒都会上报自己的offset给master,同时master也会保存每个slave的offset。这个倒不是说特定就用在全量复制,主要是master和slave都要知道各自的数据的offset,才能知道互相之间的数据不一致的情况。
backlog
backlog主要是用来做全量复制中断后的增量复制的,master node有一个backlog,默认是1MB大小,master node给slave node复制数据时,也会将数据在backlog中同步写一份。
master run_id介绍
info server可以看到master run_id,如果是根据host+ip定位master node,是不靠谱的,如果master node重启或者数据出现了变化,那么slave node应该根据不同的run_id区分,run_id不同就做全量复制,如果需要不更改run_id重启redis,可以使用redis-cli debug reload命令。psync
从节点使用psync从master node进行复制,psync runid offset,master node会根据自身的情况返回响应信息,可能是FULLRESYNC runid offset触发全量复制,可能是CONTINUE触发增量复制。
全量复制
rdb生成、rdb通过网络拷贝、slave旧数据的清理、slave aof rewrite,其实都很耗费时间,如果复制的数据量在4G~6G之间,那么很可能全量复制时间消耗到1分半到2分钟。
- master执行bgsave,在本地生成一份rdb快照文件
- master node将rdb快照文件发送给salve node,如果rdb复制时间超过60秒(repl-timeout),那么slave node就会认为复制失败,可以适当调节大这个参数。
- 对于千兆网卡的机器,一般每秒传输100MB,6G文件,很可能超过60s。
- master node在生成rdb时,会将所有新的写命令缓存在内存中,在salve node保存了rdb之后,再将新的写命令复制给salve node。
- 配置解释:
client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间,内存缓冲区持续消耗超过64MB,或者一次性超过256MB,那么停止复制,复制失败。 - slave node接收到rdb之后,清空自己的旧数据,然后重新加载rdb到自己的内存中,同时基于旧的数据版本对外提供服务。
- 如果slave node开启了AOF,那么会立即执行
BGREWRITEAOF,重写AOF。
增量复制
- 如果全量复制过程中,master-slave网络连接断掉,那么slave重新连接master时,会触发增量复制。
- master直接从自己的backlog中获取部分丢失的数据,发送给slave node,默认backlog就是1MB。
- msater就是根据slave发送的psync中的offset来从backlog中获取数据的。
heartbeat
主从节点互相都会发送heartbeat信息,master默认每隔10秒发送一次heartbeat,salve node每隔1秒发送一个heartbeat。
异步复制
master每次接收到写命令之后,现在内部写入数据,然后异步发送给slave node。
Redis读写分离架构实战
上面的内容都是在铺垫各种redis replication的原理和知识,主从架构,读写分离。接下来就跟随文章进行项目应用实战,搭建一个一主一从的架构,主节点去写,从节点去读。
配置从节点,需要在从节点的redis.conf配置文件中修改slaveof ip port。
我这里配置成slaveof eshop-cache01 6379。
强制读写分离配置:slave节点只读是默认开启的,slave-read-only yes,开启了只读的redis slave node,会拒绝所有的写操作,这样可以强制搭建成读写分离的架构。
如果master有密码,还需要配置masterauth,来授权从节点访问。
读写分离架构的测试
先启动主节点,eshop-cache01上的redis实例,再启动从节点,eshop-cache02上的redis实例。(eshop-cache01和eshop-cache02是我配置的2台虚拟机。)
!!千万要注意一点,redis的默认配置中,是处于开发模式的,从别的机器是无法访问的,所以要修改bind配置,把它先注释掉吧。
bind 127.0.0.1
然后用redis-cli连接从节点,info replication可以看到当前节点集群的配置信息。
1 | 127.0.0.1:6379> info replication |
连接主节点:
1 | 127.0.0.1:6379> info replication |
在主节点set k1 v2,从节点get k1,马上就能看到结果,数据已经同步过去了。
QPS测试
如果想要对刚才搭建的Redis集群做一个基准的测试,测一下性能和QPS(query per second)。Redis自己提供了redis-benchmark压测工具,这是最快捷最方便的,当然了,这个工具比较简单,只能用一些简单的操作和场景去压测。
对redis读写分离架构进行压测,单实例写QPS+单实例读QPS(我是1核1G的虚拟机)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274redis-4.0.8/src/redis-benchmark -h localhost
-c <clients> Number of parallel connections (default 50)
-n <requests> Total number of requests (default 100000)
-d <size> Data size of SET/GET value in bytes (default 2)
====== PING_INLINE ======
100000 requests completed in 1.05 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.81% <= 1 milliseconds
99.93% <= 2 milliseconds
100.00% <= 2 milliseconds
95602.30 requests per second
====== PING_BULK ======
100000 requests completed in 1.14 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.57% <= 1 milliseconds
99.87% <= 2 milliseconds
99.99% <= 3 milliseconds
100.00% <= 3 milliseconds
87489.06 requests per second
====== SET ======
100000 requests completed in 1.23 seconds
50 parallel clients
3 bytes payload
keep alive: 1
98.93% <= 1 milliseconds
99.75% <= 2 milliseconds
100.00% <= 3 milliseconds
81499.59 requests per second
====== GET ======
100000 requests completed in 1.30 seconds
50 parallel clients
3 bytes payload
keep alive: 1
96.70% <= 1 milliseconds
99.20% <= 2 milliseconds
99.78% <= 3 milliseconds
99.97% <= 4 milliseconds
100.00% <= 5 milliseconds
100.00% <= 5 milliseconds
76863.95 requests per second
====== INCR ======
100000 requests completed in 1.51 seconds
50 parallel clients
3 bytes payload
keep alive: 1
95.39% <= 1 milliseconds
98.90% <= 2 milliseconds
99.73% <= 3 milliseconds
99.93% <= 4 milliseconds
100.00% <= 4 milliseconds
66093.85 requests per second
====== LPUSH ======
100000 requests completed in 1.36 seconds
50 parallel clients
3 bytes payload
keep alive: 1
97.80% <= 1 milliseconds
99.54% <= 2 milliseconds
99.81% <= 3 milliseconds
99.86% <= 4 milliseconds
99.89% <= 5 milliseconds
99.90% <= 6 milliseconds
99.90% <= 8 milliseconds
99.93% <= 9 milliseconds
99.95% <= 10 milliseconds
99.97% <= 11 milliseconds
99.98% <= 12 milliseconds
100.00% <= 12 milliseconds
73260.07 requests per second
====== RPUSH ======
100000 requests completed in 1.21 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.79% <= 1 milliseconds
100.00% <= 1 milliseconds
82781.45 requests per second
====== LPOP ======
100000 requests completed in 1.24 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.19% <= 1 milliseconds
99.73% <= 2 milliseconds
99.92% <= 3 milliseconds
99.95% <= 4 milliseconds
99.99% <= 5 milliseconds
100.00% <= 5 milliseconds
80645.16 requests per second
====== RPOP ======
100000 requests completed in 1.15 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.67% <= 1 milliseconds
99.84% <= 2 milliseconds
99.91% <= 3 milliseconds
99.95% <= 4 milliseconds
99.97% <= 5 milliseconds
100.00% <= 5 milliseconds
86730.27 requests per second
====== SADD ======
100000 requests completed in 1.72 seconds
50 parallel clients
3 bytes payload
keep alive: 1
94.97% <= 1 milliseconds
98.39% <= 2 milliseconds
99.20% <= 3 milliseconds
99.50% <= 4 milliseconds
99.58% <= 5 milliseconds
99.59% <= 6 milliseconds
99.63% <= 7 milliseconds
99.67% <= 8 milliseconds
99.68% <= 9 milliseconds
99.74% <= 10 milliseconds
99.75% <= 11 milliseconds
99.75% <= 12 milliseconds
99.76% <= 13 milliseconds
99.78% <= 14 milliseconds
99.83% <= 15 milliseconds
99.83% <= 16 milliseconds
99.86% <= 17 milliseconds
99.89% <= 23 milliseconds
99.90% <= 24 milliseconds
99.93% <= 25 milliseconds
99.93% <= 27 milliseconds
99.93% <= 31 milliseconds
99.94% <= 33 milliseconds
99.95% <= 41 milliseconds
99.95% <= 42 milliseconds
99.95% <= 43 milliseconds
99.96% <= 44 milliseconds
99.99% <= 46 milliseconds
99.99% <= 49 milliseconds
100.00% <= 52 milliseconds
100.00% <= 55 milliseconds
100.00% <= 56 milliseconds
58038.30 requests per second
====== HSET ======
100000 requests completed in 1.26 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.09% <= 1 milliseconds
99.97% <= 2 milliseconds
100.00% <= 2 milliseconds
79617.84 requests per second
====== SPOP ======
100000 requests completed in 1.25 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.30% <= 1 milliseconds
99.97% <= 2 milliseconds
100.00% <= 2 milliseconds
80000.00 requests per second
====== LPUSH (needed to benchmark LRANGE) ======
100000 requests completed in 1.27 seconds
50 parallel clients
3 bytes payload
keep alive: 1
98.56% <= 1 milliseconds
99.89% <= 2 milliseconds
99.97% <= 3 milliseconds
100.00% <= 4 milliseconds
78616.35 requests per second
====== LRANGE_100 (first 100 elements) ======
100000 requests completed in 1.17 seconds
50 parallel clients
3 bytes payload
keep alive: 1
98.44% <= 1 milliseconds
99.83% <= 2 milliseconds
99.96% <= 3 milliseconds
99.99% <= 4 milliseconds
100.00% <= 4 milliseconds
85616.44 requests per second
====== LRANGE_300 (first 300 elements) ======
100000 requests completed in 1.24 seconds
50 parallel clients
3 bytes payload
keep alive: 1
97.47% <= 1 milliseconds
99.55% <= 2 milliseconds
99.76% <= 3 milliseconds
99.89% <= 4 milliseconds
99.95% <= 5 milliseconds
99.95% <= 15 milliseconds
99.95% <= 16 milliseconds
99.98% <= 17 milliseconds
100.00% <= 18 milliseconds
100.00% <= 28 milliseconds
100.00% <= 28 milliseconds
80906.15 requests per second
====== LRANGE_500 (first 450 elements) ======
100000 requests completed in 1.16 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.01% <= 1 milliseconds
99.78% <= 2 milliseconds
99.88% <= 3 milliseconds
99.99% <= 4 milliseconds
100.00% <= 4 milliseconds
86355.79 requests per second
====== LRANGE_600 (first 600 elements) ======
100000 requests completed in 1.08 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.17% <= 1 milliseconds
99.82% <= 2 milliseconds
99.90% <= 3 milliseconds
99.96% <= 4 milliseconds
99.98% <= 5 milliseconds
100.00% <= 8 milliseconds
100.00% <= 8 milliseconds
92250.92 requests per second
====== MSET (10 keys) ======
100000 requests completed in 1.28 seconds
50 parallel clients
3 bytes payload
keep alive: 1
96.11% <= 1 milliseconds
98.95% <= 2 milliseconds
99.49% <= 3 milliseconds
99.70% <= 4 milliseconds
99.76% <= 5 milliseconds
99.86% <= 6 milliseconds
99.94% <= 7 milliseconds
99.96% <= 8 milliseconds
99.98% <= 10 milliseconds
100.00% <= 10 milliseconds
78369.91 requests per second到了环境中,QPS就不一定能有这么高了,因为网络本身就有开销,还有QPS两大杀手,一个是lrange操作,还有就是如果value很大,也比较费时。
水平扩容redis读节点,提升度吞吐量
再在其他服务器上搭建redis从节点,单个从节点读请QPS在5万左右,两个redis从节点,所有的读请求到两台机器上去,承载整个集群读QPS在10万+。
总结
本文系统讲解了Redis缓存架构的关键技术要点。通过合理的缓存设计和持久化配置,可以有效提升系统性能和数据安全性。建议根据实际业务场景选择合适的缓存策略,并做好监控和运维工作。
关键要点
- 理解缓存架构的核心设计原则
- 掌握Redis持久化机制的配置方法
- 学习企业级缓存方案的最佳实践
实践建议
- 根据业务特点选择合适的持久化策略
- 建立完善的监控和告警机制
- 定期备份和演练故障恢复流程